
GitHub - ScriptFUSION/Porter: :lipstick: Durable and asynchronous data imports for consuming data at scale and publishing testable SDKs.:lipstick: Durable and asynchronous data imports for consuming data at scale and publishing testable SDKs. - ScriptFUSION/Porter
Visit Site
GitHub - ScriptFUSION/Porter: :lipstick: Durable and asynchronous data imports for consuming data at scale and publishing testable SDKs.
Porter
![]()
![]()
![]()
![]()

Durable and asynchronous data imports for consuming data at scale and publishing testable SDKs
Porter is the all-purpose PHP data importer. She fetches data from APIs, web scraping or anywhere and serves it as an iterable record collection, encouraging processing one record at a time instead of loading full data sets into memory. Durability features provide automatic, transparent recovery from intermittent network errors by default.
Porter's interface triad of providers, resources and connectors allows us to publish testable SDKs and maps well to APIs and HTTP endpoints. For example, a typical API such as GitHub would define the provider as GitHubProvider, a resource as GetUser or ListRepositories and the connector could be HttpConnector.
Porter supports asynchronous imports via fibers(PHP 8.1) allowing multiple imports to be started, paused and resumed concurrently. Async allows us to import data as fast as possible, transforming applications from network-bound (slow) to CPU-bound (optimal). Throttle support ensures we do not exceed peer connection or throughput limits.
Porter network quick links



Contents
- Benefits
- Quick start
- About this manual
- Usage
- Porter's API
- Overview
- Import specifications
- Record collections
- Asynchronous
- Transformers
- Filtering
- Durability
- Caching
- Architecture
- Providers
- Resources
- Connectors
- Limitations
- Testing
- Contributing
- License
Benefits
- Defines an easily testable interface triad for data imports: providers represent one or more resources that fetch data from connectors. These interfaces make it very easy to test and mock specific parts of the import lifecycle using industry standard tools, whether we want to mock at the connector level and feed in raw responses or mock at the resource level and supply ready-hydrated objects.
- Provides memory-efficient data processing interfaces that handle large data sets one record at a time, via iterators, which can be implemented using deferred execution with generators.
- Asynchronous imports offer highly efficient CPU-bound data processing for large scale imports across multiple connections concurrently, eliminating network latency performance bottlenecks. Concurrency can be rate-limited using throttling.
- Protects against intermittent network failures with durability features that transparently and automatically retry failed data fetches.
- Offers post-import transformations, such as filtering and mapping, to transform third-party data into useful data for our applications.
- Supports PSR-6 caching, at the connector level, for each fetch operation.
- Joins two or more linked data sets together using sub-imports automatically.
Quick start
To get started quickly, consuming an existing Porter provider, try one of our quick start guides:
- General quickstart – Get started using Porter with vanilla PHP (no framework) and the European Central Bank provider.
- Symfony quickstart – Get started by integrating Porter into a new Symfony project with the Steam provider.
For a more thorough introduction continue reading.
About this manual
Those consuming a Porter provider create one instance of Porter for their application and an instance of Import for each data import they wish to perform. Those publishing providers must implement Provider and ProviderResource.
The first half of this manual covers Porter's main API for consuming data services. The second half covers architecture, interface and implementation details for publishing data services. There's an intermission in-between, so you'll know where the separation is!
Text marked as inline code denotes literal code, as it would appear in a PHP file. For example, Porter refers specifically to the class of the same name within this library, whereas Porter refers to this project as a whole.
Usage
Creating the container
Create a new Porter instance—we'll usually only need one per application. Porter's constructor requires a PSR-11 compatible ContainerInterface that acts as a repository of providers.
When integrating Porter into a typical MVC framework application, we'll usually have a service locator or DI container implementing this interface already. We can simply inject the entire container into Porter, although it's best practice to create a separate container just for Porter's providers. For an example of doing this correctly in Symfony, see the Symfony quickstart.
Without a framework, pick any PSR-11 compatible library and inject an instance of its container class. We could even write our own container since the interface is easy to implement, but using an existing library is beneficial, particularly since most support lazy-loading of services. If you're not sure which to use, Joomla DI seems fairly simple and light.
Registering providers
Configure the container by registering one or more Porter providers. In this example we'll add the ECB provider for foreign exchange rates. Most provider libraries will export just one provider class; in this case it's EuropeanCentralBankProvider. We could add the provider to the container by writing something similar to $container->set(EuropeanCentralBankProvider::class, new EuropeanCentralBankProvider), but consult the manual for your particular container implementation for the exact syntax.
It is recommended to use the provider's class name as the container service name, as in the example in the previous paragraph. Porter will retrieve the service matching the provider's class name by default, so this reduces friction when getting started. If we use a different service name, it will need to be configured on the Import by calling setProviderName().
Importing data
Porter's import method accepts an Import that describes which data should be imported and how the data should be transformed. To import DailyForexRates without applying any transformations we can write the following.
$records = $porter->import(new Import(new DailyForexRates));
Calling import() returns an instance of PorterRecords or CountablePorterRecords, which both implement Iterator, allowing each record in the collection to be enumerated using foreach as in the following example.
foreach ($records as $record) {
var_dump($record);
}
Porter's API
Porter's simple API comprises data import methods that must always be used to begin imports, instead of calling methods directly on providers or resources, in order to take advantage of Porter's features correctly.
Porter provides just two public methods for importing data. These are the methods to be most familiar with, where the life of a data import operation begins.
import(Import): PorterRecords|CountablePorterRecords– Imports one or more records from the resource contained in the specified import specification. If the total size of the collection is known, the record collection may implementCountable, otherwisePorterRecordsis returned.importOne(Import): ?array– Imports one record from the resource contained in the specified import specification. If more than one record is imported,ImportExceptionis thrown. Use this when a provider implementsSingleRecordResource, returning just a single record.
Overview
The following data flow diagram gives a high level overview of Porter's main interfaces and the data flows between them when importing data. Note that we use the term resource for brevity, but the interface is actually called ProviderResource, because resource is a reserved word in PHP.
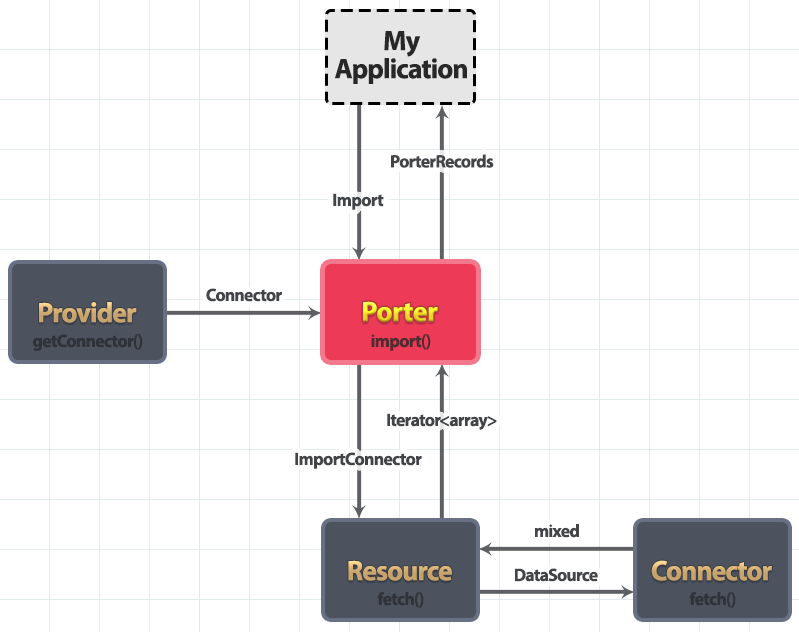
Our application calls Porter::import() with an Import and receives PorterRecords back. Everything else happens internally, so we don't need to worry about it unless writing custom providers, resources or connectors.
Import specifications
Import specifications specify what to import, how it should be transformed and whether to use caching. Create a new instance of Import and pass a ProviderResource that specifies the resource we want to import.
Options may be configured using the methods below.
setProviderName(string)– Sets the provider service name.addTransformer(Transformer)– Adds a transformer to the end of the transformation queue.addTransformers(Transformer[])– Adds one or more transformers to the end of the transformation queue.setContext(mixed)– Specifies user-defined data to be passed to transformers.enableCache()– Enables caching. Requires aCachingConnector.setMaxFetchAttempts(int)– Sets the maximum number of fetch attempts per connection before failure is considered permanent.setFetchExceptionHandler(FetchExceptionHandler)– Sets the exception handler invoked each time a fetch attempt fails.setThrottle(Throttle)– Sets the connection throttle, invoked each time a connector fetches data.
Record collections
Record collections are Iterators, guaranteeing imported data is enumerable using foreach. Each record of the collection is the familiar and flexible array type, allowing us to present structured or flat data, such as JSON, XML or CSV, as an array.
Details
Record collections may be Countable, depending on whether the imported data was countable and whether any destructive operations were performed after import. Filtering is a destructive operation since it may remove records and therefore the count reported by a ProviderResource would no longer be accurate. It is the responsibility of the resource to supply the total number of records in its collection by returning an iterator that implements Countable, such as ArrayIterator, or more commonly, CountableProviderRecords. When a countable iterator is used, Porter returns CountablePorterRecords, provided no destructive operations were performed.
Record collections are composed by Porter using the decorator pattern. If provider data is not modified, PorterRecords will decorate the ProviderRecords returned from a ProviderResource. That is, PorterRecords has a pointer back to the previous collection, which could be written as: PorterRecords → ProviderRecords. If a filter was applied, the collection stack would be PorterRecords → FilteredRecords → ProviderRecords. Normally this is an unimportant detail but can sometimes be useful for debugging.
The stack of record collection types informs us of the transformations a collection has undergone and each type holds a pointer to relevant objects that participated in the transformation. For example, PorterRecords holds a reference to the Import that was used to create it and can be accessed using PorterRecords::getImport.
Metadata
Since record collections are just objects, it is possible to define derived types that implement custom fields to expose additional metadata in addition to the iterated data. Collections are very good at representing a repeating series of data but some APIs send additional non-repeating data which we can expose as metadata. However, if the data is not repeating at all, it should be treated as a single record rather than metadata.
The result of a successful Porter::import call is always an instance of PorterRecords or CountablePorterRecords, depending on whether the number of records is known. If we need to access methods of the original collection, returned by the provider, we can call findFirstCollection() on the collection. For an example, see CurrencyRecords of the European Central Bank Provider and its associated test case.
Asynchronous
Porter has had asynchronous support since version 5 (2019) thanks to Amp integration. In v5, async was implemented with coroutines, but from version 6 onwards, Porter uses the simpler fibers model. Fiber support is included in PHP 8.1 and can be added to PHP 8.0 using ext-fiber. PHP 7 does not support fibers, so if you are stuck with that version of PHP, coroutines are the only option. It is strongly recommended to upgrade to PHP 8.1 to use async, to avoid unnecessary bugs leading to segfaults and to avoid getting trapped in the coroutine architecture that is cumbersome to upgrade, difficult to debug and harder to reason about.
In version 5, Porter offered a dual API to support the asynchronous code path. That is, Porter::import had the async analogue: Porter::importAsync and Porter::importOne had Porter::importOneAsync. In version 6 we switched to fibers but kept the dual API to making migrating from coroutines to fibers slightly easier. Since version 7, we unified the dual API because async with fibers can be almost entirely transparent: the synchronous and asynchronous code paths are identical, so we don't even have to think about async unless and until we want to start leveraging its benefits in our application.
To use async in Porter v7 onwards, simply wrap an import() or importOne() call in an async() call using one of the following two methods.
use function Amp\async;
async(
$this->porter->import(...),
new Import(new MyResource())
);
// -OR-
async(fn () => $this->porter->import(new Import(new MyResource()));
In order for this to work, the only requirement is that the underlying connector supports fibers. To know whether a particular connector supports fibers, consult its documentation. The most common connector, HttpConnector, already has fiber support.
Calling async() returns a Future representing the eventual result of an asynchronous operation. To understand how futures are composed and abstracted, or how to await and iterate collections of futures, is beyond the scope of this document. Full details about async programming can be found in the official Amp documentation.
Note: At the time of writing, Amp v3 is still in beta, so you may find it necessary to lower a project's minimum stability to include Amp packages, via
composer.json:"minimum-stability": "beta"To avoid pulling in any betas other than those absolutely necessary for the dependency solver to be satisfied, it is recommended to also set stable packages as the preferred stability when using the above setting.
"prefer-stable": true
Throttling
The asynchronous import model is very powerful because it changes our application's performance model from I/O-bound, limited by the speed of the network, to CPU-bound, limited by the speed of the CPU. In the traditional synchronous model, each import operation must wait for the previous to complete before the next begins, meaning the total import time depends on how long it takes each import's network I/O to finish. In the async model, since we send many requests concurrently without waiting for the previous to complete. On average, each import operation only takes as long as our CPU takes to process it, since we are busy processing another import during network latency (except during the initial "spin-up").
Synchronously, we seldom trip protection measures even for high volume imports, however the naïve approach to asynchronous imports is often fraught with perils. If we import 10,000 HTTP resources at once, one of two things usually happens: either we run out of PHP memory and the process terminates prematurely or the HTTP server rejects us after sending too many requests in a short period. The solution is throttling.
Async Throttle is included with Porter to throttle asynchronous imports. The throttle works by preventing additional operations starting when too many are executing concurrently, based on user-defined limits. By default, NullThrottle is assigned, which does not throttle connections. DualThrottle can be used to set two independent connection rate limits: the maximum number of connections per second and the maximum number of concurrent connections.
A DualThrottle can be assigned by modifying the import specification as follows.
(new Import)->setThrottle(new DualThrottle)
ThrottledConnector
A throttle can be assigned to a connector implementing the ThrottledConnector interface. This allows a provider to apply a throttle to all its resources by default. When a throttle is assigned to both a connector and an import specification, the specification's throttle takes priority. If the connector we want to use does not implement ThrottledConnector, simply extend the connector and implement the interface.
Implementing ThrottledConnector is likely to be preferable when we want many resources to share the same throttle or when we want to inject the throttle using dependency injection, since specifications are typically instantiated inline whereas connectors are not. That is, we would usually declare connectors in our application framework's service configuration.
Transformers
Transformers manipulate imported data. Transforming data is useful because third-party data seldom arrives in a format that looks exactly as we want. Transformers are added to the transformation queue of an Import by calling its addTransformer method and are executed in the order they are added.
Porter includes one transformer, FilterTransformer, that removes records from the collection based on a predicate. For more information, see filtering. More powerful data transformations can be designed with MappingTransformer. More transformers may be available from Porter transformers.
Writing a transformer
Transformers implement the Transformer and/or AsyncTransformer interfaces that define one or more of the following methods.
public function transform(RecordCollection $records, mixed $context): RecordCollection;
public function transformAsync(AsyncRecordCollection $records, mixed $context): AsyncRecordCollection;
When transform() or transformAsync() is called the transformer may iterate each record and change it in any way, including removing or inserting additional records. The record collection must be returned by the method, whether or not changes were made.
Transformers should also implement the __clone magic method if they store any object state, in order to facilitate deep copy when Porter clones the owning Import during import.
Filtering
Filtering provides a way to remove some records. For each record, if the specified predicate function returns false (or a falsy value), the record will be removed, otherwise the record will be kept. The predicate receives the current record as an array as its first parameter and context as its second parameter.
In general, we would like to avoid filtering because it is inefficient to import data and then immediately remove some of it, but some immature APIs do not provide a way to reduce the data set on the server, so filtering on the client is the only alternative. Filtering also invalidates the record count reported by some resources, meaning we no longer know how many records are in the collection before iteration.
Example
The following example filters out any records that do not have an id field present.
$records = $porter->import(
(new Import(new MyResource))
->addTransformer(
new FilterTransformer(static function (array $record) {
return array_key_exists('id', $record);
})
)
);
Durability
Porter automatically retries connections when an exception occurs during Connector::fetch. This helps mitigate intermittent network conditions that cause temporary data fetch failures. The number of retry attempts can be configured by calling the setMaxFetchAttempts method of an Import.
The default exception handler, ExponentialSleepFetchExceptionHandler, causes a failed fetch to pause the entire program for a series of increasing delays, doubling each time. Given that the default number of retry attempts is five, the exception handler may be called up to four times, delaying each retry attempt for ~0.1, ~0.2, ~0.4, and finally, ~0.8 seconds. After the fifth and final failure, FailingTooHardException is thrown.
The exception handler can be changed by calling setFetchExceptionHandler. For example, the following code changes the initial retry delay to one second.
$specification->setFetchExceptionHandler(new ExponentialSleepFetchExceptionHandler(1000000));
Durability only applies when connectors throw a recoverable exception type derived from RecoverableConnectorException. If an unexpected exception occurs the fetch attempt will be aborted. For more information, see implementing connector durability. Exception handlers receive the thrown exception as their first argument. An exception handler can inspect the recoverable exception and throw its own exception if it decides the exception should be treated as fatal instead of recoverable.
Caching
Any connector can be wrapped in a CachingConnector to provide PSR-6 caching facilities to the base connector. Porter ships with one cache implementation, MemoryCache, which caches fetched data in memory, but this can be substituted for any other PSR-6 cache implementation. The CachingConnector caches raw responses for each unique request, where uniqueness is determined by DataSource::computeHash.
Remember that whilst using a CachingConnector enables caching, caching must also be enabled on a per-import basis by calling Import::enableCache().
Example
The follow example enables connector caching.
$records = $porter->import(
(new Import(new MyResource))
->enableCache()
);
INTERMISSION ☕️
Congratulations! We have covered everything needed to use Porter.
The rest of this readme is for those wishing to go deeper. Continue when you're ready to learn how to write providers, resources and connectors.
Architecture
The following UML class diagram shows a partial architectural overview illustrating Porter's main components and how they are related. Asynchronous implementation details are mostly omitted since they mirror the synchronous system. [enlarge]

Providers
Providers supply their ProviderResource objects with a Connector. The provider must ensure it supplies a connector of the correct type for accessing its service's resources. A provider implements Provider that defines one method with the following signature.
public function getConnector() : Connector;
A provider does not know how many resources it has nor maintains a list of such resources and neither does any other part of Porter. That is, a resource class can be created at any time and claim to belong to a given provider without any formal registration.
Writing a provider
Providers must implement the Provider interface and supply a valid connector when getConnector is called. From Porter's perspective, writing a provider often requires little more than supplying the correct type hint when storing a connector instance, but we can embellish the class with any other features we may want. For HTTP service providers, it is common to add a base URL constant and some static methods to compose URLs, reducing code duplication in its resources.
Implementation example
In the following example we create a provider that only accepts HttpConnector instances. We also create a default connector in case one is not supplied. Note it is not always possible to create a default connector, and it is perfectly valid to insist the caller supplies a connector.
final class MyProvider implements Provider
{
private $connector;
public function __construct(Connector $connector = null)
{
$this->connector = $connector ?: new HttpConnector;
}
public function getConnector(): Connector
{
return $this->connector;
}
}
Resources
Resources fetch data using the supplied connector and format it as a collection of arrays. A resource implements ProviderResource that defines the following three methods.
public function getProviderClassName(): string;
public function fetch(ImportConnector $connector): \Iterator;
A resource supplies the class name of the provider it expects a connector from when getProviderClassName() is called.
When fetch() is called it is passed the connector from which data must be fetched. The resource must ensure data is formatted as an iterator of array values whilst remaining as true to the original format as possible; that is, we must avoid renaming or restructuring data because it is the caller's prerogative to perform data customization if desired. The recommended way to return an iterator is to use yield to implicitly return a Generator, which has the added benefit of processing one record at a time.
The fetch method receives an ImportConnector, which is a runtime wrapper for the underlying connector supplied by the provider. This wrapper is used to isolate the connector's state from the rest of the application. Since PHP doesn't have native immutability support, working with cloned state is the only way we can guarantee unexpected changes do not occur once an import has started. This means it's safe to import one resource, make changes to the connector's settings and then start another import before the first has completed. Providers can also safely make changes to the underlying connector by calling getWrappedConnector(), because the wrapped connector is cloned as soon as ImportConnector is constructed.
Providing immutability via cloning is an important concept because resources are often implemented using generators, which implies delayed code execution. Multiple fetches can be started with different settings, but execute in a different order some time later when they're finally enumerated. This issue will become even more pertinent when Porter supports asynchronous fetches, enabling multiple fetches to execute concurrently. However, we don't need to worry about this implementation detail unless writing a connector ourselves.
Writing a resource
Resources must implement the ProviderResource interface. getProviderClassName() usually returns a hard-coded provider class name and fetch() must always return an iterator of array values.
In this contrived example that uses dummy data and ignores the connector, suppose we want to return the numeric series one to three: the following implementation would be invalid because it returns an iterator of integer values instead of an iterator of array values.
public function fetch(ImportConnector $connector): \Iterator
{
return new ArrayIterator(range(1, 3)); // Invalid return type.
}
Either of the following fetch() implementations would be valid.
public function fetch(ImportConnector $connector): \Iterator
{
foreach (range(1, 3) as $number) {
yield [$number];
}
}
Since the total number of records is known, the iterator can be wrapped in CountableProviderRecords to enrich the caller with this information.
public function fetch(ImportConnector $connector): \Iterator
{
$series = function ($limit) {
foreach (range(1, $limit) as $number) {
yield [$number];
}
};
return new CountableProviderRecords($series($count = 3), $count, $this);
}
Implementation example
In the following example we create a resource that receives a connector from MyProvider and uses it to retrieve data from a hard-coded URL. We expect the data to be JSON encoded so we decode it into an array and use yield to return it as a single-item iterator.
class MyResource implements ProviderResource, SingleRecordResource
{
private const URL = 'https://example.com';
public function getProviderClassName(): string
{
return MyProvider::class;
}
public function fetch(ImportConnector $connector): \Iterator
{
$data = $connector->fetch(self::URL);
yield json_decode($data, true);
}
}
If the data represents a repeating series, yield each record separately instead, as in the following example, and remove the SingleRecordResource marker interface.
public function fetch(ImportConnector $connector): \Iterator
{
$data = $connector->fetch(self::URL);
foreach (json_decode($data, true) as $datum) {
yield $datum;
}
}
Exception handling
Unrecoverable exceptions will be thrown and can be caught as normal, but good connector implementations will wrap their connection attempts in a retry block and throw a RecoverableConnectorException. The only way to intercept a recoverable exception is by attaching a FetchExceptionHandler to the ImportConnector by calling its setExceptionHandler() method. Exception handlers cannot be used for flow control because their return values are ignored, so the main application of such handlers is to re-throw recoverable exceptions as non-recoverable exceptions.
Connectors
Connectors fetch remote data from a source specified at fetch time. Connectors for popular protocols are available from Porter connectors. It might be necessary to write a new connector if dealing with uncommon or currently unsupported protocols. Writing providers and resources is a common task that should be fairly easy but writing a connector is less common.
Writing a connector
A connector implements the Connector interface that defines one method with the following signature.
public function fetch(DataSource $source): mixed;
When fetch() is called the connector fetches data from the specified data source. Connectors may return data in any format that's convenient for resources to consume, but in general, such data should be as raw as possible and without modification. If multiple pieces of information are returned it is recommended to use a specialized object, like the HttpResponse returned by the HTTP connector that contains the response headers and body together.
Data sources
The DataSource interface must be implemented to supply the necessary parameters for a connector to locate a data source. For an HTTP connector, this might include URL, method, body and headers. For a database connector, this might be a SQL query.
DataSource specifies one method with the following signature.
public function computeHash(): string;
Data sources are required to return a unique hash for their state. If the state changes, the hash must change. If states are effectively equivalent, the hash must be the same. This is used by the cache system to determine whether the fetch operation has been seen before and thus can be served from the cache rather than fetching fresh data again.
It is important to define a canonical order for hashed inputs such that identical state presented in different orders does not create different hash values. For example, we might sort HTTP headers alphabetically before hashing because header order is not significant and reordering headers should not produce different output.
Durability
To support Porter's durability features a connector may throw a subclass of RecoverableConnectorException to signal that the fetch operation can be retried. Execution will halt as normal if any other exception type is thrown. It is recommended to throw a recoverable exception type when the fetch operation is idempotent.
Limitations
Current limitations that may affect some users and should be addressed in the near future.
- No end-to-end data steaming interface.
Testing
Porter is fully unit and mutation tested.
- Run unit tests with the
composer testcommand. - Run mutation tests with the
composer mutationcommand.
Contributing
Everyone is welcome to contribute anything, from ideas and issues to code and documentation!
License
Porter is published under the open source GNU Lesser General Public License v3.0. However, the original Porter character and artwork is copyright © 2022 Bilge and may not be reproduced or modified without express written permission.
Support
Porter is supported by JetBrains for Open Source products.

Quick links
More Resourcesto explore the angular.
mail [email protected] to add your project or resources here 🔥.
- 1Non-blocking I/O Streams in PHP
https://amphp.org/byte-streamLearn how to stream data (ordered sequences of bytes) concurrently in PHP. - 2Private Packagist
https://packagist.com/Composer package archive as a service for PHP - 3Nette – Comfortable and Safe Web Development in PHP
https://nette.orgNette is a family of mature and stand-alone components for PHP. Ready to be smitten? Together, they create a framework that had been rated as the 3rd most popular in the world. Our philosophy is to focus on productivity, best practices, and security. - 4Jenkins and PHP
https://www.jenkins.io/solutions/php/.Jenkins – an open source automation server which enables developers around the world to reliably build, test, and deploy their software - 5Laravel Zero
https://laravel-zero.comMicro-framework for console applications - 6Spiral Framework
https://spiral.dev/High-Performance PHP framework for modern enterprise application development. - 7Private Packages | repman.io | Private PHP Package Repository Manager
https://repman.ioAdd and manage private PHP Composer dependencies in cloud or behind your firewall - 8Sulu, the Symfony CMS
https://sulu.io/Deliver awesome, robust, reliable websites with Sulu CMS. The ideal combination of PHP developer experience and agency platform. A Full-Stack Symfony CMS for enterprise projects. - 9Pest | The elegant PHP testing framework
https://pestphp.com/Pest is a testing framework with a focus on simplicity, meticulously designed to bring back the joy of testing in PHP. - 10PHP Open Source Project
https://www.doctrine-project.org/The Doctrine Project is an open-source PHP project that is home to home to several PHP libraries primarily focused on database storage and object mapping. The core projects are the Object Relational Mapper (ORM) and the Database Abstraction Layer (DBAL) it is built upon. - 11Drupal - Open Source CMS
https://www.drupal.orgDrupal - the leading open-source CMS for ambitious digital experiences that reach your audience across multiple channels. Because we all have different needs, Drupal allows you to create a unique space in a world of cookie-cutter solutions. - 12CakePHP - Build fast, grow solid | PHP Framework | Home
https://cakephp.org/CakePHP is an open-source web, rapid development framework that makes building web applications simpler, faster and require less code. It follows the model–view–controller (MVC) . Manual for beginners now available and links towards the last version. - 13PHP AST Viewer
https://php-ast-viewer.com/The PHP AST Viewer is a tool for viewing the Abstract Syntax Tree of PHP code. By visualizing the structure, it helps developers gain a deeper understanding of the code, thus improving code quality and maintenance efficiency. - 14Application Monitoring & Error Tracking for Developers
https://www.honeybadger.io/Full-stack application monitoring and error tracking that helps small teams move fast and fix things. - 15Geocoder PHP
https://geocoder-php.org/The most featured Geocoder library written in PHP - 16Tideways
https://tideways.com/Your mission control center for PHP application performance Tideways saves you time by taking the guesswork out of your app's backend performance. Gain detailed insights, spot performance bottlenecks, and get real-time error detection alerts. Start Trial Spend more time shipping and less time stuck on bottlenecks. Experience your application from the customer’s point of view. [...] - 17High Performance PHP Framework - Phalcon Framework
https://phalcon.io/en-usOfficial Phalcon Documentation - 18We’ve Acquired Shippable to Complete DevOps Pipeline Automation From Code to Production
https://jfrog.com/blog/weve-acquired-shippable-to-complete-devops-pipeline-automation-from-code-to-production/The only platform for DevOps automation that covers the complete pipeline, end-to-end, JFrog, now also with Shippable inside. - 19Livewire | Laravel
https://livewire.laravel.com/A full-stack framework for Laravel that takes the pain out of building dynamic UIs. - 20Committed to open source
https://spatie.be/open-sourceAt Spatie, we’re big on open source. It’s not just a way of working for us, it's part of our culture. - 21App Monitoring, Error Tracking & Real User Monitoring
https://www.bugsnag.com/BugSnag is an error monitoring and reporting software with best-in-class functionality for mobile apps. Our tool alerts users of bugs, errors & more. Free trial! - 22Fast, Reliable Email Delivery Service | SMTP | API
https://postmarkapp.comSend transactional and marketing emails and get them to the inbox on time, every time. Postmark is a fast and reliable email delivery service for developers. - 23Jenkins
https://www.jenkins.io/Jenkins – an open source automation server which enables developers around the world to reliably build, test, and deploy their software - 24Home
https://rollbar.com/Rollbar provides real-time error tracking & debugging tools for developers. ✓ JavaScript ✓PHP ✓Ruby ✓Python ✓Java ✓Android ✓iOS ✓.NET & more. - 25PSR HTTP Message implementations
https://github.com/laminas/laminas-diactorosPSR HTTP Message implementations. Contribute to laminas/laminas-diactoros development by creating an account on GitHub. - 26A configurable and extensible PHP web spider
https://github.com/mvdbos/php-spiderA configurable and extensible PHP web spider. Contribute to mvdbos/php-spider development by creating an account on GitHub. - 27Mailchimp Transactional API | Mailchimp
https://mailchimp.com/features/transactional-email/.Send personalized, event-driven messages at scale with the speed and reliability of Mailchimp. - 28Simple, Flexible, Trustworthy CI/CD Tools - Travis CI
https://www.travis-ci.comTravis CI is the most simple and flexible ci/cd tool available today. Find out how Travis CI can help with continuous integration and continuous delivery. - 29Kirby is the CMS that adapts to you
https://getkirby.com/Kirby is the content management system that adapts to any project. Made for developers, designers, creators and clients. - 30GenPhrase is a secure passphrase generator for PHP applications.
https://github.com/timoh6/GenPhraseGenPhrase is a secure passphrase generator for PHP applications. - timoh6/GenPhrase - 31PHP Object Model Manager for Postgresql
https://github.com/chanmix51/PommPHP Object Model Manager for Postgresql. Contribute to chanmix51/Pomm development by creating an account on GitHub. - 32PHP Library to generate random passwords
https://github.com/hackzilla/password-generatorPHP Library to generate random passwords. Contribute to hackzilla/password-generator development by creating an account on GitHub. - 33PHP Secure Headers
https://github.com/BePsvPT/secure-headersPHP Secure Headers. Contribute to bepsvpt/secure-headers development by creating an account on GitHub. - 34A PSR-15 server request handler.
https://github.com/relayphp/Relay.RelayA PSR-15 server request handler. Contribute to relayphp/Relay.Relay development by creating an account on GitHub. - 35Simple library that abstracts different metrics collectors. I find this necessary to have a consistent and simple metrics (functional) API that doesn't cause vendor lock-in.
https://github.com/beberlei/metricsSimple library that abstracts different metrics collectors. I find this necessary to have a consistent and simple metrics (functional) API that doesn't cause vendor lock-in. - beberlei/metrics - 36Software Engineering Intelligence
https://codeclimate.comCode Climate's industry-leading Software Engineering Intelligence platform helps unlock the full potential of your organization to ship better code,… - 37PHP ETL - parquet library
https://github.com/flow-php/parquetPHP ETL - parquet library . Contribute to flow-php/parquet development by creating an account on GitHub. - 38Continuous Integration and Delivery
https://about.gitlab.com/solutions/continuous-integration/Make software delivery repeatable and on-demand - 39A static php code analysis tool using the Graph Theory
https://github.com/Trismegiste/MondrianA static php code analysis tool using the Graph Theory - Trismegiste/Mondrian - 40Compatibility with the password_* functions that ship with PHP 5.5
https://github.com/ircmaxell/password_compatCompatibility with the password_* functions that ship with PHP 5.5 - ircmaxell/password_compat - 41Slim Framework 4 Skeleton Application
https://github.com/slimphp/Slim-SkeletonSlim Framework 4 Skeleton Application. Contribute to slimphp/Slim-Skeleton development by creating an account on GitHub. - 42[READ-ONLY] URI manipulation Library
https://github.com/thephpleague/uri[READ-ONLY] URI manipulation Library. Contribute to thephpleague/uri development by creating an account on GitHub. - 43Simple Encryption in PHP.
https://github.com/defuse/php-encryptionSimple Encryption in PHP. Contribute to defuse/php-encryption development by creating an account on GitHub. - 44ImageWorkshop is a PHP5.3+ library that helps you to manage images based on GD library
https://github.com/Sybio/ImageWorkshopImageWorkshop is a PHP5.3+ library that helps you to manage images based on GD library - Sybio/ImageWorkshop - 45A Mustache implementation in PHP.
https://github.com/bobthecow/mustache.phpA Mustache implementation in PHP. Contribute to bobthecow/mustache.php development by creating an account on GitHub. - 46Easily parse your project's Composer configuration, and those of its dependencies, at runtime
https://github.com/joshdifabio/composedEasily parse your project's Composer configuration, and those of its dependencies, at runtime - joshdifabio/composed - 47vfsStream is a stream wrapper for a virtual file system that may be helpful in unit tests to mock the real file system. It can be used with any unit test framework, like PHPUnit or SimpleTest.
https://github.com/bovigo/vfsStreamvfsStream is a stream wrapper for a virtual file system that may be helpful in unit tests to mock the real file system. It can be used with any unit test framework, like PHPUnit or SimpleTest. - bo... - 48Simple composer script to manage phar files using project composer.json.
https://github.com/tommy-muehle/tooly-composer-scriptSimple composer script to manage phar files using project composer.json. - tommy-muehle/tooly-composer-script - 49Show unused composer dependencies by scanning your code
https://github.com/composer-unused/composer-unusedShow unused composer dependencies by scanning your code - composer-unused/composer-unused - 50GeoJSON implementation for PHP
https://github.com/jmikola/geojsonGeoJSON implementation for PHP. Contribute to jmikola/geojson development by creating an account on GitHub. - 51XHProf is a function-level hierarchical profiler for PHP and has a simple HTML based user interface.
https://github.com/phacility/xhprofXHProf is a function-level hierarchical profiler for PHP and has a simple HTML based user interface. - phacility/xhprof - 52Automatic SQL injection and database takeover tool
https://github.com/sqlmapproject/sqlmapAutomatic SQL injection and database takeover tool - sqlmapproject/sqlmap - 53Modern, Crazy Fast, Ridiculously Easy and Amazingly Powerful Flat-File CMS powered by PHP, Markdown, Twig, and Symfony
https://github.com/getgrav/gravModern, Crazy Fast, Ridiculously Easy and Amazingly Powerful Flat-File CMS powered by PHP, Markdown, Twig, and Symfony - getgrav/grav - 54PHP 7.1 ready Smart and Simple Documentation for your PHP project
https://github.com/apigen/apigenPHP 7.1 ready Smart and Simple Documentation for your PHP project - ApiGen/ApiGen - 55PHP Mocking Framework
https://github.com/phake/phakePHP Mocking Framework. Contribute to phake/phake development by creating an account on GitHub. - 56A web router implementation for PHP.
https://github.com/auraphp/Aura.RouterA web router implementation for PHP. Contribute to auraphp/Aura.Router development by creating an account on GitHub. - 57Library for using online Email providers
https://github.com/Stampie/StampieLibrary for using online Email providers. Contribute to Stampie/Stampie development by creating an account on GitHub. - 58:earth_asia: Functions for making sense out of URIs in PHP
https://github.com/sabre-io/uri:earth_asia: Functions for making sense out of URIs in PHP - sabre-io/uri - 59A minimalist framework for command-line applications in PHP
https://github.com/minicli/minicliA minimalist framework for command-line applications in PHP - minicli/minicli - 60PHP's lightweight HTTP client
https://github.com/kriswallsmith/BuzzPHP's lightweight HTTP client. Contribute to kriswallsmith/Buzz development by creating an account on GitHub. - 61A static analysis tool for finding errors in PHP applications
https://github.com/vimeo/psalmA static analysis tool for finding errors in PHP applications - vimeo/psalm - 62Javascript Minifier built in PHP
https://github.com/tedious/JShrinkJavascript Minifier built in PHP . Contribute to tedious/JShrink development by creating an account on GitHub. - 63Event package for your app and domain
https://github.com/thephpleague/eventEvent package for your app and domain. Contribute to thephpleague/event development by creating an account on GitHub. - 64PHP Architecture Tester - Easy architecture testing for PHP :heavy_check_mark:
https://github.com/carlosas/phpatPHP Architecture Tester - Easy architecture testing for PHP :heavy_check_mark: - carlosas/phpat - 65A data mapper implementation for your persistence model in PHP.
https://github.com/atlasphp/Atlas.OrmA data mapper implementation for your persistence model in PHP. - atlasphp/Atlas.Orm - 66A super lightweight PSR-7 implementation
https://github.com/Nyholm/psr7A super lightweight PSR-7 implementation. Contribute to Nyholm/psr7 development by creating an account on GitHub. - 67Helps sending emails
https://github.com/symfony/mailerHelps sending emails. Contribute to symfony/mailer development by creating an account on GitHub. - 68PHP library for parsing plain text email content.
https://github.com/willdurand/EmailReplyParserPHP library for parsing plain text email content. Contribute to willdurand/EmailReplyParser development by creating an account on GitHub. - 69Slim Framework 2 custom views
https://github.com/slimphp/Slim-ViewsSlim Framework 2 custom views. Contribute to slimphp/Slim-Views development by creating an account on GitHub. - 70A tool for creating configurable dumps of large MySQL-databases.
https://github.com/webfactory/slimdumpA tool for creating configurable dumps of large MySQL-databases. - webfactory/slimdump - 71PHP Compatibility check for PHP_CodeSniffer
https://github.com/PHPCompatibility/PHPCompatibilityPHP Compatibility check for PHP_CodeSniffer. Contribute to PHPCompatibility/PHPCompatibility development by creating an account on GitHub. - 72A PHP project/micro-package generator for PDS compliant projects or micro-packages.
https://github.com/jonathantorres/constructA PHP project/micro-package generator for PDS compliant projects or micro-packages. - jonathantorres/construct - 73PHP Payment processing library. It offers everything you need to work with payments: Credit card & offsite purchasing, subscriptions, payouts etc.
https://github.com/payum/payumPHP Payment processing library. It offers everything you need to work with payments: Credit card & offsite purchasing, subscriptions, payouts etc. - Payum/Payum - 74PCOV - CodeCoverage compatible driver for PHP
https://github.com/krakjoe/pcovPCOV - CodeCoverage compatible driver for PHP. Contribute to krakjoe/pcov development by creating an account on GitHub. - 75Guzzle, an extensible PHP HTTP client
https://github.com/guzzle/guzzleGuzzle, an extensible PHP HTTP client. Contribute to guzzle/guzzle development by creating an account on GitHub. - 76Transactional Email API Service For Developers | Mailgun
https://www.mailgun.com/Powerful Transactional Email APIs that enable you to send, receive, and track emails, built with developers in mind. Learn more today! - 77PHP Extension installer
https://github.com/FriendsOfPHP/picklePHP Extension installer. Contribute to FriendsOfPHP/pickle development by creating an account on GitHub. - 78🕷 CrawlerDetect is a PHP class for detecting bots/crawlers/spiders via the user agent
https://github.com/JayBizzle/Crawler-Detect🕷 CrawlerDetect is a PHP class for detecting bots/crawlers/spiders via the user agent - JayBizzle/Crawler-Detect - 79Manages URL generation and versioning of web assets such as CSS stylesheets, JavaScript files and image files
https://github.com/symfony/assetManages URL generation and versioning of web assets such as CSS stylesheets, JavaScript files and image files - symfony/asset - 80Iteration primitives using generators
https://github.com/nikic/iterIteration primitives using generators. Contribute to nikic/iter development by creating an account on GitHub. - 81A tool to automatically fix PHP Coding Standards issues
https://github.com/PHP-CS-Fixer/PHP-CS-FixerA tool to automatically fix PHP Coding Standards issues - PHP-CS-Fixer/PHP-CS-Fixer - 82Mock built-in PHP functions (e.g. time(), exec() or rand())
https://github.com/php-mock/php-mockMock built-in PHP functions (e.g. time(), exec() or rand()) - php-mock/php-mock - 83Full-stack testing PHP framework
https://github.com/Codeception/CodeceptionFull-stack testing PHP framework. Contribute to Codeception/Codeception development by creating an account on GitHub. - 84PHPGGC is a library of PHP unserialize() payloads along with a tool to generate them, from command line or programmatically.
https://github.com/ambionics/phpggcPHPGGC is a library of PHP unserialize() payloads along with a tool to generate them, from command line or programmatically. - GitHub - ambionics/phpggc: PHPGGC is a library of PHP unserialize() p... - 85Image optimization / compression library. This library is able to optimize png, jpg and gif files in very easy and handy way. It uses optipng, pngquant, pngcrush, pngout, gifsicle, jpegoptim and jpegtran tools.
https://github.com/psliwa/image-optimizerImage optimization / compression library. This library is able to optimize png, jpg and gif files in very easy and handy way. It uses optipng, pngquant, pngcrush, pngout, gifsicle, jpegoptim and jp... - 86Simple patches plugin for Composer
https://github.com/cweagans/composer-patchesSimple patches plugin for Composer. Contribute to cweagans/composer-patches development by creating an account on GitHub. - 87CaptainHook is a very flexible git hook manager for software developers that makes sharing git hooks with your team a breeze.
https://github.com/captainhookphp/captainhookCaptainHook is a very flexible git hook manager for software developers that makes sharing git hooks with your team a breeze. - captainhookphp/captainhook - 88Reactive extensions for PHP
https://github.com/ReactiveX/RxPHPReactive extensions for PHP. Contribute to ReactiveX/RxPHP development by creating an account on GitHub. - 89Primitives for functional programming in PHP
https://github.com/lstrojny/functional-phpPrimitives for functional programming in PHP. Contribute to lstrojny/functional-php development by creating an account on GitHub. - 90A PHP code-quality tool
https://github.com/phpro/grumphpA PHP code-quality tool. Contribute to phpro/grumphp development by creating an account on GitHub. - 91Doctrine2 behavioral extensions, Translatable, Sluggable, Tree-NestedSet, Timestampable, Loggable, Sortable
https://github.com/doctrine-extensions/DoctrineExtensionsDoctrine2 behavioral extensions, Translatable, Sluggable, Tree-NestedSet, Timestampable, Loggable, Sortable - doctrine-extensions/DoctrineExtensions - 92SQL database access through PDO.
https://github.com/auraphp/Aura.SqlSQL database access through PDO. Contribute to auraphp/Aura.Sql development by creating an account on GitHub. - 93stackphp
https://github.com/stackphpstackphp has 8 repositories available. Follow their code on GitHub. - 94PHP implementation of Fowler's Money pattern.
https://github.com/moneyphp/moneyPHP implementation of Fowler's Money pattern. Contribute to moneyphp/money development by creating an account on GitHub. - 95Multi target HAML (HAML for PHP, Twig, <your language here>)
https://github.com/arnaud-lb/MtHamlMulti target HAML (HAML for PHP, Twig, <your language here>) - arnaud-lb/MtHaml - 96Manage mailboxes, filter/get/delete emails in PHP (supports IMAP/POP3/NNTP)
https://github.com/barbushin/php-imapManage mailboxes, filter/get/delete emails in PHP (supports IMAP/POP3/NNTP) - barbushin/php-imap - 97A password policy enforcer for PHP and JavaScript
https://github.com/ircmaxell/password-policyA password policy enforcer for PHP and JavaScript. Contribute to ircmaxell/password-policy development by creating an account on GitHub. - 98A Simple PHP Renderer for Slim 3 & 4 (or any other PSR-7 project)
https://github.com/slimphp/PHP-ViewA Simple PHP Renderer for Slim 3 & 4 (or any other PSR-7 project) - slimphp/PHP-View - 99CSV data manipulation made easy in PHP
https://github.com/thephpleague/csvCSV data manipulation made easy in PHP. Contribute to thephpleague/csv development by creating an account on GitHub. - 100PHP 7.4 EventStore Implementation
https://github.com/prooph/event-storePHP 7.4 EventStore Implementation. Contribute to prooph/event-store development by creating an account on GitHub. - 101:crystal_ball: Better Reflection is a reflection API that aims to improve and provide more features than PHP's built-in reflection API.
https://github.com/Roave/BetterReflection:crystal_ball: Better Reflection is a reflection API that aims to improve and provide more features than PHP's built-in reflection API. - Roave/BetterReflection - 102Provides mechanisms for walking through any arbitrary PHP variable
https://github.com/symfony/var-dumperProvides mechanisms for walking through any arbitrary PHP variable - symfony/var-dumper - 103Laravel Pint is an opinionated PHP code style fixer for minimalists.
https://github.com/laravel/pintLaravel Pint is an opinionated PHP code style fixer for minimalists. - laravel/pint - 104PHP Magic Number Detector
https://github.com/povils/phpmndPHP Magic Number Detector. Contribute to povils/phpmnd development by creating an account on GitHub. - 105A static analyzer for PHP version migration
https://github.com/monque/PHP-MigrationA static analyzer for PHP version migration. Contribute to monque/PHP-Migration development by creating an account on GitHub. - 106Read and write spreadsheet files (CSV, XLSX and ODS), in a fast and scalable way
https://github.com/openspout/openspoutRead and write spreadsheet files (CSV, XLSX and ODS), in a fast and scalable way - GitHub - openspout/openspout: Read and write spreadsheet files (CSV, XLSX and ODS), in a fast and scalable way - 107A standalone DateTime library originally based off of Carbon
https://github.com/cakephp/chronosA standalone DateTime library originally based off of Carbon - cakephp/chronos - 108Symfony, High Performance PHP Framework for Web Development
https://symfony.com/Symfony is a set of reusable PHP components and a PHP framework to build web applications, APIs, microservices and web services. - 109Provides powerful methods to fetch HTTP resources synchronously or asynchronously
https://github.com/symfony/http-clientProvides powerful methods to fetch HTTP resources synchronously or asynchronously - symfony/http-client - 110A tool for quickly measuring the size of a PHP project.
https://github.com/sebastianbergmann/phplocA tool for quickly measuring the size of a PHP project. - sebastianbergmann/phploc - 111Manage all your cron jobs without modifying crontab. Handles locking, logging, error emails, and more.
https://github.com/jobbyphp/jobbyManage all your cron jobs without modifying crontab. Handles locking, logging, error emails, and more. - jobbyphp/jobby - 112PHP Static Analysis Tool - discover bugs in your code without running it!
https://github.com/phpstan/phpstanPHP Static Analysis Tool - discover bugs in your code without running it! - phpstan/phpstan - 113PHP errors for cool kids
https://github.com/filp/whoopsPHP errors for cool kids . Contribute to filp/whoops development by creating an account on GitHub. - 114[READ ONLY] Subtree split of the Illuminate Database component (see laravel/framework)
https://github.com/illuminate/database[READ ONLY] Subtree split of the Illuminate Database component (see laravel/framework) - illuminate/database - 115Micro PHP benchmark library
https://github.com/devster/ubenchMicro PHP benchmark library. Contribute to devster/ubench development by creating an account on GitHub. - 116Event-driven, non-blocking I/O with PHP.
https://github.com/reactphp/reactphpEvent-driven, non-blocking I/O with PHP. Contribute to reactphp/reactphp development by creating an account on GitHub. - 117Keep your architecture clean.
https://github.com/qossmic/deptracKeep your architecture clean. Contribute to qossmic/deptrac development by creating an account on GitHub. - 118:currency_exchange: Currency exchange rates library
https://github.com/florianv/swap:currency_exchange: Currency exchange rates library - florianv/swap - 119A pure PHP library for reading and writing presentations documents
https://github.com/PHPOffice/PHPPresentationA pure PHP library for reading and writing presentations documents - GitHub - PHPOffice/PHPPresentation: A pure PHP library for reading and writing presentations documents - 120The Laravel Components
https://github.com/illuminateThe Laravel Components has 38 repositories available. Follow their code on GitHub. - 121Fast request router for PHP
https://github.com/nikic/FastRouteFast request router for PHP. Contribute to nikic/FastRoute development by creating an account on GitHub. - 122Prior to making any Submission(s), you must sign an Adobe Contributor License Agreement, available here at: https://opensource.adobe.com/cla.html. All Submissions you make to Adobe Inc. and its affiliates, assigns and subsidiaries (collectively “Adobe”) are subject to the terms of the Adobe Contributor License Agreement.
https://github.com/magento/magento2Prior to making any Submission(s), you must sign an Adobe Contributor License Agreement, available here at: https://opensource.adobe.com/cla.html. All Submissions you make to Adobe Inc. and its aff... - 123Événement is a very simple event dispatching library for PHP.
https://github.com/igorw/evenementÉvénement is a very simple event dispatching library for PHP. - igorw/evenement - 124Menu Library for PHP
https://github.com/KnpLabs/KnpMenuMenu Library for PHP. Contribute to KnpLabs/KnpMenu development by creating an account on GitHub. - 125Next-gen phpDoc parser with support for intersection types and generics
https://github.com/phpstan/phpdoc-parserNext-gen phpDoc parser with support for intersection types and generics - phpstan/phpdoc-parser - 126Beautiful and understandable static analysis tool for PHP
https://github.com/phpmetrics/PhpMetricsBeautiful and understandable static analysis tool for PHP - phpmetrics/PhpMetrics - 127Golang's defer statement for PHP
https://github.com/php-defer/php-deferGolang's defer statement for PHP. Contribute to php-defer/php-defer development by creating an account on GitHub. - 128The Exakat Engine : smart static analysis for PHP
https://github.com/exakat/exakatThe Exakat Engine : smart static analysis for PHP. Contribute to exakat/exakat development by creating an account on GitHub. - 129Mockery is a simple yet flexible PHP mock object framework for use in unit testing with PHPUnit, PHPSpec or any other testing framework. Its core goal is to offer a test double framework with a succinct API capable of clearly defining all possible object operations and interactions using a human readable Domain Specific Language (DSL).
https://github.com/mockery/mockeryMockery is a simple yet flexible PHP mock object framework for use in unit testing with PHPUnit, PHPSpec or any other testing framework. Its core goal is to offer a test double framework with a suc... - 130SendGrid Email API and Email Marketing Campaigns | SendGrid
https://sendgrid.com/en-usSend at scale with SendGrid’s trusted email API and marketing campaigns platform, delivering 148+ billion emails for senders like you every month. - 131HTML to PDF converter for PHP
https://github.com/dompdf/dompdfHTML to PDF converter for PHP. Contribute to dompdf/dompdf development by creating an account on GitHub. - 132:globe_with_meridians: List of all countries with names and ISO 3166-1 codes in all languages and data formats.
https://github.com/umpirsky/country-list:globe_with_meridians: List of all countries with names and ISO 3166-1 codes in all languages and data formats. - umpirsky/country-list - 133WordPress, Git-ified. This repository is just a mirror of the WordPress subversion repository. Please do not send pull requests. Submit pull requests to https://github.com/WordPress/wordpress-develop and patches to https://core.trac.wordpress.org/ instead.
https://github.com/WordPress/WordPressWordPress, Git-ified. This repository is just a mirror of the WordPress subversion repository. Please do not send pull requests. Submit pull requests to https://github.com/WordPress/wordpress-devel... - 134PHP Image Processing
https://github.com/Intervention/imagePHP Image Processing. Contribute to Intervention/image development by creating an account on GitHub. - 135PHP Benchmarking framework
https://github.com/phpbench/phpbenchPHP Benchmarking framework. Contribute to phpbench/phpbench development by creating an account on GitHub. - 136Infrastructure and testing helpers for creating CQRS and event sourced applications.
https://github.com/broadway/broadwayInfrastructure and testing helpers for creating CQRS and event sourced applications. - broadway/broadway - 137Sample code for several design patterns in PHP 8.x
https://github.com/DesignPatternsPHP/DesignPatternsPHPSample code for several design patterns in PHP 8.x - DesignPatternsPHP/DesignPatternsPHP - 138PHPMD is a spin-off project of PHP Depend and aims to be a PHP equivalent of the well known Java tool PMD. PHPMD can be seen as an user friendly frontend application for the raw metrics stream measured by PHP Depend.
https://github.com/phpmd/phpmdPHPMD is a spin-off project of PHP Depend and aims to be a PHP equivalent of the well known Java tool PMD. PHPMD can be seen as an user friendly frontend application for the raw metrics stream meas... - 139PHP DataMapper, ORM
https://github.com/cycle/ormPHP DataMapper, ORM. Contribute to cycle/orm development by creating an account on GitHub. - 140A pure PHP library for reading and writing word processing documents
https://github.com/PHPOffice/PHPWordA pure PHP library for reading and writing word processing documents - PHPOffice/PHPWord - 141📦🚀 Fast, zero config application bundler with PHARs.
https://github.com/box-project/box📦🚀 Fast, zero config application bundler with PHARs. - box-project/box - 142Modern task runner for PHP
https://github.com/consolidation/RoboModern task runner for PHP. Contribute to consolidation/robo development by creating an account on GitHub. - 143A simple but powerful API for processing & compiling assets built around Webpack
https://github.com/symfony/webpack-encoreA simple but powerful API for processing & compiling assets built around Webpack - symfony/webpack-encore - 144PHPCheckstyle is an open-source tool that helps PHP programmers adhere to certain coding conventions.
https://github.com/PHPCheckstyle/phpcheckstylePHPCheckstyle is an open-source tool that helps PHP programmers adhere to certain coding conventions. - PHPCheckstyle/phpcheckstyle - 145The power of webpack, distilled for the rest of us.
https://github.com/laravel-mix/laravel-mixThe power of webpack, distilled for the rest of us. - laravel-mix/laravel-mix - 146Continuous Integration & Delivery - Semaphore
https://semaphoreci.comSemaphore CI/CD helps product teams deliver software with high standards of quality, security, and efficiency. - 147Send events to a socket.io server through PHP
https://github.com/ElephantIO/elephant.ioSend events to a socket.io server through PHP. Contribute to ElephantIO/elephant.io development by creating an account on GitHub. - 148Xdebug — Step Debugger and Debugging Aid for PHP
https://github.com/xdebug/xdebugXdebug — Step Debugger and Debugging Aid for PHP. Contribute to xdebug/xdebug development by creating an account on GitHub. - 149Mainly a PHP Language Server with more features than you can shake a stick at
https://github.com/phpactor/phpactorMainly a PHP Language Server with more features than you can shake a stick at - phpactor/phpactor - 150A PHP parser written in PHP
https://github.com/nikic/PHP-ParserA PHP parser written in PHP. Contribute to nikic/PHP-Parser development by creating an account on GitHub. - 151PHP Debug Console
https://github.com/Seldaek/php-consolePHP Debug Console. Contribute to Seldaek/php-console development by creating an account on GitHub. - 152IoC Dependency Injector
https://github.com/rdlowrey/AurynIoC Dependency Injector. Contribute to rdlowrey/auryn development by creating an account on GitHub. - 153A library for generating and validating passwords
https://github.com/ircmaxell/PHP-PasswordLibA library for generating and validating passwords. Contribute to ircmaxell/PHP-PasswordLib development by creating an account on GitHub. - 154Small PHP library to valid email addresses using a number of methods.
https://github.com/nojacko/email-validatorSmall PHP library to valid email addresses using a number of methods. - nojacko/email-validator - 155PHP library allowing thumbnail, snapshot or PDF generation from a url or a html page. Wrapper for wkhtmltopdf/wkhtmltoimage
https://github.com/KnpLabs/snappyPHP library allowing thumbnail, snapshot or PDF generation from a url or a html page. Wrapper for wkhtmltopdf/wkhtmltoimage - KnpLabs/snappy - 156Independent query builders for MySQL, PostgreSQL, SQLite, and Microsoft SQL Server.
https://github.com/auraphp/Aura.SqlQueryIndependent query builders for MySQL, PostgreSQL, SQLite, and Microsoft SQL Server. - auraphp/Aura.SqlQuery - 157League\Pipeline
https://github.com/thephpleague/pipelineLeague\Pipeline. Contribute to thephpleague/pipeline development by creating an account on GitHub. - 158A tool to verify that your files are in harmony with your .editorconfig
https://github.com/editorconfig-checker/editorconfig-checker.phpA tool to verify that your files are in harmony with your .editorconfig - editorconfig-checker/editorconfig-checker.php - 159Static code analysis to find violations in a dependency graph
https://github.com/mamuz/PhpDependencyAnalysisStatic code analysis to find violations in a dependency graph - mamuz/PhpDependencyAnalysis - 160🤖 Id obfuscation based on Knuth's multiplicative hashing method for PHP.
https://github.com/jenssegers/optimus🤖 Id obfuscation based on Knuth's multiplicative hashing method for PHP. - jenssegers/optimus - 161㊙️ AntiXSS | Protection against Cross-site scripting (XSS) via PHP
https://github.com/voku/anti-xss㊙️ AntiXSS | Protection against Cross-site scripting (XSS) via PHP - voku/anti-xss - 162Shopware 6 is an open commerce platform based on Symfony Framework and Vue and supported by a worldwide community and more than 1.500 community extensions
https://github.com/shopware/shopwareShopware 6 is an open commerce platform based on Symfony Framework and Vue and supported by a worldwide community and more than 1.500 community extensions - shopware/shopware - 163Html menu generator
https://github.com/spatie/menuHtml menu generator. Contribute to spatie/menu development by creating an account on GitHub. - 164An asynchronous event driven PHP socket framework. Supports HTTP, Websocket, SSL and other custom protocols.
https://github.com/walkor/WorkermanAn asynchronous event driven PHP socket framework. Supports HTTP, Websocket, SSL and other custom protocols. - GitHub - walkor/workerman: An asynchronous event driven PHP socket framework. Support... - 165The easy PHP Library for calculating holidays
https://github.com/azuyalabs/yasumiThe easy PHP Library for calculating holidays. Contribute to azuyalabs/yasumi development by creating an account on GitHub. - 166Main repository for maintaining Shopsys Platform packages. Open for ISSUES and PULL REQUESTS.
https://github.com/shopsys/shopsys/Main repository for maintaining Shopsys Platform packages. Open for ISSUES and PULL REQUESTS. - GitHub - shopsys/shopsys: Main repository for maintaining Shopsys Platform packages. Open for ISSUES... - 167Validates passwords against PHP's password_hash function using PASSWORD_DEFAULT. Will rehash when needed, and will upgrade legacy passwords with the Upgrade decorator.
https://github.com/jeremykendall/password-validatorValidates passwords against PHP's password_hash function using PASSWORD_DEFAULT. Will rehash when needed, and will upgrade legacy passwords with the Upgrade decorator. - jeremykendall/password-... - 168CssToInlineStyles is a class that enables you to convert HTML-pages/files into HTML-pages/files with inline styles. This is very usefull when you're sending emails.
https://github.com/tijsverkoyen/CssToInlineStylesCssToInlineStyles is a class that enables you to convert HTML-pages/files into HTML-pages/files with inline styles. This is very usefull when you're sending emails. - tijsverkoyen/CssToInlineSt... - 169Get info from any web service or page
https://github.com/oscarotero/EmbedGet info from any web service or page. Contribute to oscarotero/Embed development by creating an account on GitHub. - 170Fast PSR-7 based routing and dispatch component including PSR-15 middleware, built on top of FastRoute.
https://github.com/thephpleague/routeFast PSR-7 based routing and dispatch component including PSR-15 middleware, built on top of FastRoute. - thephpleague/route - 171Object-Oriented API for PHP streams
https://github.com/fzaninotto/StreamerObject-Oriented API for PHP streams. Contribute to fzaninotto/Streamer development by creating an account on GitHub. - 172A money and currency library for PHP
https://github.com/brick/moneyA money and currency library for PHP. Contribute to brick/money development by creating an account on GitHub. - 173😎 Tracy: the addictive tool to ease debugging PHP code for cool developers. Friendly design, logging, profiler, advanced features like debugging AJAX calls or CLI support. You will love it.
https://github.com/nette/tracy😎 Tracy: the addictive tool to ease debugging PHP code for cool developers. Friendly design, logging, profiler, advanced features like debugging AJAX calls or CLI support. You will love it. - nette... - 174Handle PHP errors, dump variables, execute PHP code remotely in Google Chrome
https://github.com/barbushin/php-consoleHandle PHP errors, dump variables, execute PHP code remotely in Google Chrome - barbushin/php-console - 175Simple Yet Powerful Geo Library for PHP
https://github.com/mjaschen/phpgeoSimple Yet Powerful Geo Library for PHP. Contribute to mjaschen/phpgeo development by creating an account on GitHub. - 176Simple and fast HTML and XML parser
https://github.com/Imangazaliev/DiDOMSimple and fast HTML and XML parser. Contribute to Imangazaliev/DiDOM development by creating an account on GitHub. - 177Extract colors from an image like a human would do.
https://github.com/thephpleague/color-extractorExtract colors from an image like a human would do. - thephpleague/color-extractor - 178:closed_lock_with_key: Security advisories as a simple composer exclusion list, updated daily
https://github.com/Roave/SecurityAdvisories:closed_lock_with_key: Security advisories as a simple composer exclusion list, updated daily - Roave/SecurityAdvisories - 179Pux is a fast PHP Router and includes out-of-box controller tools
https://github.com/c9s/PuxPux is a fast PHP Router and includes out-of-box controller tools - c9s/Pux - 180Small but powerful dependency injection container
https://github.com/thephpleague/containerSmall but powerful dependency injection container. Contribute to thephpleague/container development by creating an account on GitHub. - 181Public Suffix List based domain parsing implemented in PHP
https://github.com/jeremykendall/php-domain-parserPublic Suffix List based domain parsing implemented in PHP - jeremykendall/php-domain-parser - 182A simple PHP API extension for DateTime.
https://github.com/briannesbitt/CarbonA simple PHP API extension for DateTime. Contribute to briannesbitt/Carbon development by creating an account on GitHub. - 183RMT is a handy tool to help releasing new version of your software
https://github.com/liip/RMTRMT is a handy tool to help releasing new version of your software - liip/RMT - 184SpecBDD Framework for PHP
https://github.com/phpspec/phpspecSpecBDD Framework for PHP. Contribute to phpspec/phpspec development by creating an account on GitHub. - 185PHPCI is a free and open source continuous integration tool specifically designed for PHP.
https://github.com/dancryer/phpciPHPCI is a free and open source continuous integration tool specifically designed for PHP. - dancryer/PHPCI - 186Daux.io is an documentation generator that uses a simple folder structure and Markdown files to create custom documentation on the fly. It helps you create great looking documentation in a developer friendly way.
https://github.com/dauxio/daux.ioDaux.io is an documentation generator that uses a simple folder structure and Markdown files to create custom documentation on the fly. It helps you create great looking documentation in a develope... - 187An IMAP library for PHP
https://github.com/tedious/FetchAn IMAP library for PHP. Contribute to tedious/Fetch development by creating an account on GitHub. - 188Dependency Injection System
https://github.com/auraphp/Aura.DiDependency Injection System. Contribute to auraphp/Aura.Di development by creating an account on GitHub. - 189Production-grade rapid controller development with built in love for API and Search
https://github.com/friendsofcake/crudProduction-grade rapid controller development with built in love for API and Search - FriendsOfCake/crud - 190Baum is an implementation of the Nested Set pattern for Laravel's Eloquent ORM.
https://github.com/etrepat/baumBaum is an implementation of the Nested Set pattern for Laravel's Eloquent ORM. - etrepat/baum - 191Compares two source sets and determines the appropriate semantic versioning to apply.
https://github.com/tomzx/php-semver-checkerCompares two source sets and determines the appropriate semantic versioning to apply. - tomzx/php-semver-checker - 192[READ-ONLY] The event dispatcher library for CakePHP. This repo is a split of the main code that can be found in https://github.com/cakephp/cakephp
https://github.com/cakephp/event[READ-ONLY] The event dispatcher library for CakePHP. This repo is a split of the main code that can be found in https://github.com/cakephp/cakephp - cakephp/event - 193The classic email sending library for PHP
https://github.com/PHPMailer/PHPMailerThe classic email sending library for PHP. Contribute to PHPMailer/PHPMailer development by creating an account on GitHub. - 194Silly CLI micro-framework based on Symfony Console
https://github.com/mnapoli/sillySilly CLI micro-framework based on Symfony Console - mnapoli/silly - 195Allows you to standardize and centralize the way objects are constructed in your application
https://github.com/symfony/dependency-injectionAllows you to standardize and centralize the way objects are constructed in your application - symfony/dependency-injection - 196:white_check_mark: JoliCi - Run your TravisCi builds locally
https://github.com/jolicode/JoliCi:white_check_mark: JoliCi - Run your TravisCi builds locally - jolicode/JoliCi - 197A non-blocking concurrency framework for PHP applications. 🐘
https://github.com/amphp/ampA non-blocking concurrency framework for PHP applications. 🐘 - amphp/amp - 198PSR-7 middleware foundation for building and dispatching middleware pipelines
https://github.com/laminas/laminas-stratigilityPSR-7 middleware foundation for building and dispatching middleware pipelines - laminas/laminas-stratigility - 199Abstraction for local and remote filesystems
https://github.com/thephpleague/FlysystemAbstraction for local and remote filesystems. Contribute to thephpleague/flysystem development by creating an account on GitHub. - 200Purl is a simple Object Oriented URL manipulation library for PHP 7.2+
https://github.com/jwage/purlPurl is a simple Object Oriented URL manipulation library for PHP 7.2+ - jwage/purl - 201🌄 Perceptual image hashing for PHP
https://github.com/jenssegers/imagehash🌄 Perceptual image hashing for PHP. Contribute to jenssegers/imagehash development by creating an account on GitHub. - 202A MySQL engine written in pure PHP
https://github.com/vimeo/php-mysql-engineA MySQL engine written in pure PHP. Contribute to vimeo/php-mysql-engine development by creating an account on GitHub. - 203:lipstick: Durable and asynchronous data imports for consuming data at scale and publishing testable SDKs.
https://github.com/ScriptFUSION/Porter:lipstick: Durable and asynchronous data imports for consuming data at scale and publishing testable SDKs. - ScriptFUSION/Porter - 204Powerful implementation of the Specification pattern in PHP
https://github.com/K-Phoen/rulerzPowerful implementation of the Specification pattern in PHP - K-Phoen/rulerz - 205A browser testing and web crawling library for PHP and Symfony
https://github.com/symfony/pantherA browser testing and web crawling library for PHP and Symfony - symfony/panther - 206PHP library that provides a filesystem abstraction layer − will be a feast for your files!
https://github.com/KnpLabs/GaufrettePHP library that provides a filesystem abstraction layer − will be a feast for your files! - KnpLabs/Gaufrette - 207Checks prefer-lowest installation for actually defined min versions in composer.json
https://github.com/dereuromark/composer-prefer-lowestChecks prefer-lowest installation for actually defined min versions in composer.json - dereuromark/composer-prefer-lowest - 208Wonderfully easy on-demand image manipulation library with an HTTP based API.
https://github.com/thephpleague/glideWonderfully easy on-demand image manipulation library with an HTTP based API. - thephpleague/glide - 209A Multi-Framework Composer Library Installer
https://github.com/composer/installersA Multi-Framework Composer Library Installer. Contribute to composer/installers development by creating an account on GitHub. - 210🐘 A PHP client for interacting with Gotenberg.
https://github.com/gotenberg/gotenberg-php🐘 A PHP client for interacting with Gotenberg. Contribute to gotenberg/gotenberg-php development by creating an account on GitHub. - 211The PHP Unit Testing framework.
https://github.com/sebastianbergmann/phpunitThe PHP Unit Testing framework. Contribute to sebastianbergmann/phpunit development by creating an account on GitHub. - 212PHP Mutation Testing library
https://github.com/infection/infectionPHP Mutation Testing library. Contribute to infection/infection development by creating an account on GitHub. - 213[READ-ONLY] A flexible, lightweight and powerful Object-Relational Mapper for PHP, implemented using the DataMapper pattern. This repo is a split of the main code that can be found in https://github.com/cakephp/cakephp
https://github.com/cakephp/orm[READ-ONLY] A flexible, lightweight and powerful Object-Relational Mapper for PHP, implemented using the DataMapper pattern. This repo is a split of the main code that can be found in https://githu... - 214Highly opinionated mocking framework for PHP 5.3+
https://github.com/phpspec/prophecyHighly opinionated mocking framework for PHP 5.3+. Contribute to phpspec/prophecy development by creating an account on GitHub. - 215Simple static Composer repository generator - For a full private Composer repo use Private Packagist
https://github.com/composer/satisSimple static Composer repository generator - For a full private Composer repo use Private Packagist - composer/satis - 216UnifiedArchive - an archive manager with unified interface for different formats (bundled with cli utility). Supports all formats with basic operations (reading, extracting and creation) and popular formats specific features (compression level, password-protection, comment)
https://github.com/wapmorgan/UnifiedArchiveUnifiedArchive - an archive manager with unified interface for different formats (bundled with cli utility). Supports all formats with basic operations (reading, extracting and creation) and popula... - 217PSR-11 compatible Dependency Injection Container for PHP.
https://github.com/bitExpert/discoPSR-11 compatible Dependency Injection Container for PHP. - bitExpert/disco - 218:heavy_check_mark: PHP Test Framework for Freedom, Truth, and Justice
https://github.com/kahlan/kahlan:heavy_check_mark: PHP Test Framework for Freedom, Truth, and Justice - kahlan/kahlan - 219Build bespoke content experiences with Craft.
https://github.com/craftcms/cmsBuild bespoke content experiences with Craft. Contribute to craftcms/cms development by creating an account on GitHub. - 220Set of polyfills for changed PHPUnit functionality to allow for creating PHPUnit cross-version compatible tests
https://github.com/Yoast/PHPUnit-Polyfills/Set of polyfills for changed PHPUnit functionality to allow for creating PHPUnit cross-version compatible tests - Yoast/PHPUnit-Polyfills - 221A framework agnostic, multi-gateway payment processing library for PHP 5.6+
https://github.com/thephpleague/omnipayA framework agnostic, multi-gateway payment processing library for PHP 5.6+ - thephpleague/omnipay - 222Expressive fixtures generator
https://github.com/nelmio/aliceExpressive fixtures generator. Contribute to nelmio/alice development by creating an account on GitHub. - 223A php swagger annotation and parsing library
https://github.com/zircote/swagger-phpA php swagger annotation and parsing library. Contribute to zircote/swagger-php development by creating an account on GitHub. - 224:computer: Parallel testing for PHPUnit
https://github.com/paratestphp/paratest:computer: Parallel testing for PHPUnit. Contribute to paratestphp/paratest development by creating an account on GitHub. - 225Merge one or more additional composer.json files at Composer runtime
https://github.com/wikimedia/composer-merge-pluginMerge one or more additional composer.json files at Composer runtime - wikimedia/composer-merge-plugin - 226Yii 2: The Fast, Secure and Professional PHP Framework
https://github.com/yiisoft/yii2/Yii 2: The Fast, Secure and Professional PHP Framework - yiisoft/yii2 - 227Tester: enjoyable unit testing in PHP with code coverage reporter. 🍏🍏🍎🍏
https://github.com/nette/testerTester: enjoyable unit testing in PHP with code coverage reporter. 🍏🍏🍎🍏 - nette/tester - 228🎩✨🌈 OOP Proxy wrappers/utilities - generates and manages proxies of your objects
https://github.com/Ocramius/ProxyManager🎩✨🌈 OOP Proxy wrappers/utilities - generates and manages proxies of your objects - Ocramius/ProxyManager - 229Parse, validate, manipulate, and display dates in PHP w/ i18n support. Inspired by moment.js
https://github.com/fightbulc/moment.phpParse, validate, manipulate, and display dates in PHP w/ i18n support. Inspired by moment.js - fightbulc/moment.php - 230Kint - Advanced PHP dumper
https://github.com/kint-php/kintKint - Advanced PHP dumper. Contribute to kint-php/kint development by creating an account on GitHub. - 231🚀 Coroutine-based concurrency library for PHP
https://github.com/swoole/swoole-src🚀 Coroutine-based concurrency library for PHP. Contribute to swoole/swoole-src development by creating an account on GitHub. - 232A PHP fast CGI client for sending requests (a)synchronously to PHP-FPM
https://github.com/hollodotme/fast-cgi-clientA PHP fast CGI client for sending requests (a)synchronously to PHP-FPM - hollodotme/fast-cgi-client - 233Mautic: Open Source Marketing Automation Software.
https://github.com/mautic/mauticMautic: Open Source Marketing Automation Software. - mautic/mautic - 234Adapters for PHP framework containers to an interoperable interface
https://github.com/AcclimateContainer/acclimate-containerAdapters for PHP framework containers to an interoperable interface - AcclimateContainer/acclimate-container - 235Continuous Integration and Delivery
https://circleci.comGet the best continuous integration and delivery (CI/CD), in our cloud or on your own infrastructure. Start for free and scale as you grow. - 236PHP 5.x support for random_bytes() and random_int()
https://github.com/paragonie/random_compatPHP 5.x support for random_bytes() and random_int() - paragonie/random_compat - 237A pure PHP library for reading and writing spreadsheet files
https://github.com/PHPOffice/PhpSpreadsheetA pure PHP library for reading and writing spreadsheet files - PHPOffice/PhpSpreadsheet - 238A model factory library for creating expressive, auto-completable, on-demand dev/test fixtures with Symfony and Doctrine.
https://github.com/zenstruck/foundryA model factory library for creating expressive, auto-completable, on-demand dev/test fixtures with Symfony and Doctrine. - zenstruck/foundry - 239Asynchronous WebSocket server
https://github.com/ratchetphp/RatchetAsynchronous WebSocket server. Contribute to ratchetphp/Ratchet development by creating an account on GitHub. - 240Spot v2.x DataMapper built on top of Doctrine's Database Abstraction Layer
https://github.com/spotorm/spot2Spot v2.x DataMapper built on top of Doctrine's Database Abstraction Layer - spotorm/spot2 - 241Retrofit implementation in PHP. A REST client for PHP.
https://github.com/tebru/retrofit-phpRetrofit implementation in PHP. A REST client for PHP. - tebru/retrofit-php - 242Geo-related tools PHP 7.3+ library built atop Geocoder and React libraries
https://github.com/thephpleague/geotoolsGeo-related tools PHP 7.3+ library built atop Geocoder and React libraries - thephpleague/geotools - 243The ZAP core project
https://github.com/zaproxy/zaproxyThe ZAP core project. Contribute to zaproxy/zaproxy development by creating an account on GitHub. - 244Realistic PHP password strength estimate library based on Zxcvbn JS
https://github.com/bjeavons/zxcvbn-phpRealistic PHP password strength estimate library based on Zxcvbn JS - bjeavons/zxcvbn-php - 245The modern, simple and intuitive PHP unit testing framework.
https://github.com/atoum/atoumThe modern, simple and intuitive PHP unit testing framework. - atoum/atoum - 246🎵 Provides a composer plugin for normalizing composer.json.
https://github.com/ergebnis/composer-normalize🎵 Provides a composer plugin for normalizing composer.json. - ergebnis/composer-normalize - 247Asynchronous WebSocket client
https://github.com/ratchetphp/PawlAsynchronous WebSocket client. Contribute to ratchetphp/Pawl development by creating an account on GitHub. - 248Laravel - The PHP Framework For Web Artisans
https://laravel.com/Laravel is a PHP web application framework with expressive, elegant syntax. We’ve already laid the foundation — freeing you to create without sweating the small things. - 249Faker is a PHP library that generates fake data for you
https://github.com/fakerphp/fakerFaker is a PHP library that generates fake data for you - FakerPHP/Faker - 250A fast & flexible router
https://github.com/klein/klein.phpA fast & flexible router. Contribute to klein/klein.php development by creating an account on GitHub. - 251Sends your logs to files, sockets, inboxes, databases and various web services
https://github.com/Seldaek/monologSends your logs to files, sockets, inboxes, databases and various web services - Seldaek/monolog - 252Requests for PHP is a humble HTTP request library. It simplifies how you interact with other sites and takes away all your worries.
https://github.com/WordPress/RequestsRequests for PHP is a humble HTTP request library. It simplifies how you interact with other sites and takes away all your worries. - WordPress/Requests - 253Copy/Paste Detector (CPD) for PHP code.
https://github.com/sebastianbergmann/phpcpdCopy/Paste Detector (CPD) for PHP code. Contribute to sebastianbergmann/phpcpd development by creating an account on GitHub. - 254A CLI tool to check whether a specific composer package uses imported symbols that aren't part of its direct composer dependencies
https://github.com/maglnet/ComposerRequireCheckerA CLI tool to check whether a specific composer package uses imported symbols that aren't part of its direct composer dependencies - maglnet/ComposerRequireChecker - 255Analyze PHP code with one command
https://github.com/EdgedesignCZ/phpqaAnalyze PHP code with one command. Contribute to EdgedesignCZ/phpqa development by creating an account on GitHub. - 256Convert HTML to an image, PDF or string
https://github.com/spatie/browsershotConvert HTML to an image, PDF or string. Contribute to spatie/browsershot development by creating an account on GitHub. - 257PHP_CodeSniffer tokenizes PHP files and detects violations of a defined set of coding standards.
https://github.com/PHPCSStandards/PHP_CodeSnifferPHP_CodeSniffer tokenizes PHP files and detects violations of a defined set of coding standards. - PHPCSStandards/PHP_CodeSniffer - 258A PHP QR Code generator and reader with a user-friendly API.
https://github.com/chillerlan/php-qrcode/A PHP QR Code generator and reader with a user-friendly API. - chillerlan/php-qrcode - 259low-overhead sampling profiler for PHP 7+
https://github.com/adsr/phpspylow-overhead sampling profiler for PHP 7+. Contribute to adsr/phpspy development by creating an account on GitHub. - 260Phan is a static analyzer for PHP. Phan prefers to avoid false-positives and attempts to prove incorrectness rather than correctness.
https://github.com/phan/phanPhan is a static analyzer for PHP. Phan prefers to avoid false-positives and attempts to prove incorrectness rather than correctness. - phan/phan - 261Instant Upgrades and Automated Refactoring of any PHP 5.3+ code
https://github.com/rectorphp/rectorInstant Upgrades and Automated Refactoring of any PHP 5.3+ code - rectorphp/rector - 262An object oriented PHP driver for FFMpeg binary
https://github.com/PHP-FFmpeg/PHP-FFmpeg/An object oriented PHP driver for FFMpeg binary. Contribute to PHP-FFMpeg/PHP-FFMpeg development by creating an account on GitHub. - 263GitHub action to set up PHP with extensions, php.ini configuration, coverage drivers, and various tools.
https://github.com/shivammathur/setup-phpGitHub action to set up PHP with extensions, php.ini configuration, coverage drivers, and various tools. - shivammathur/setup-php - 264Statamic is a powerful, highly scalable CMS built on Laravel.
https://statamic.com/The open source, flat-first, Laravel + Git powered CMS designed for building easy to manage websites. - 265Symfony Components
https://symfony.com/componentsSymfony Components are a set of decoupled and reusable PHP libraries. They have become the standard foundation on which the best PHP applications are built on. - 266Sylius - eCommerce platform for custom solutions
https://sylius.com/The highest quality of code and Symfony’s unified API standards make Sylius the most customizable and integrative platform on the market. - 267Application Performance Monitoring & Error Tracking Software
https://sentry.io/welcome/Self-hosted and cloud-based application performance monitoring & error tracking that helps software teams see clearer, solve quicker, & learn continuously. - 268Build Apps On AWS Lambda
https://www.serverless.com/frameworkDeploy auto-scaling applications on AWS Lambda, API Gateway, DynamoDB, etc. Build REST APIs, GraphQL APIs, microservices, streaming data pipelines, scheduled tasks & more. - 269Homebrew
https://brew.sh/The Missing Package Manager for macOS (or Linux). - 270Bref – Simple and scalable PHP with serverless
https://bref.sh/Bref is a framework to write and deploy serverless PHP applications on AWS Lambda. - 271PHP Open Source Project
https://www.doctrine-project.org/projects/migrations.htmlPHP Doctrine Migrations project offer additional functionality on top of the database abstraction layer (DBAL) for versioning your database schema and easily deploying changes to it. It is a very easy to use and a powerful tool. - 272Manticore Search – easy-to-use fast search database
https://manticoresearch.com/Manticore Search is an easy-to-use open source fast database for search. Elasticsearch alternative, vector search, SQL interface, full-text search capabilities - 273Laradock
http://laradock.io/Full PHP development environment for Docker. - 274Hack
https://hacklang.org/Hack is an object-oriented programming language for building reliable websites at epic scale - 275Deploy your Laravel PHP application to the cloud
https://vapor.laravel.com/Laravel Vapor is a serverless deployment platform for Laravel, powered by AWS. - 276Visual Studio Code - Code Editing. Redefined
https://code.visualstudio.com/Visual Studio Code is a code editor redefined and optimized for building and debugging modern web and cloud applications. Visual Studio Code is free and available on your favorite platform - Linux, macOS, and Windows. - 277The PHP IDE by JetBrains
https://www.jetbrains.com/phpstorm/Explore the PhpStorm IDE for web projects. Get everything you need for PHP, JavaScript, and SQL coding out of the box - 278Vagrant by HashiCorp
https://www.vagrantup.com/Vagrant enables users to create and configure lightweight, reproducible, and portable development environments. - 279A simple filtering library for PHP
https://github.com/ircmaxell/filterusA simple filtering library for PHP. Contribute to ircmaxell/filterus development by creating an account on GitHub. - 280A fast PHP slug generator and transliteration library that converts non-ascii characters for use in URLs.
https://github.com/jbroadway/urlifyA fast PHP slug generator and transliteration library that converts non-ascii characters for use in URLs. - jbroadway/urlify - 281PHP library that helps to map any input into a strongly-typed value object structure.
https://github.com/CuyZ/ValinorPHP library that helps to map any input into a strongly-typed value object structure. - CuyZ/Valinor - 282:seedling: Jane is a set of libraries to generate Models & API Clients based on JSON Schema / OpenAPI specs
https://github.com/janephp/janephp/:seedling: Jane is a set of libraries to generate Models & API Clients based on JSON Schema / OpenAPI specs - janephp/janephp - 2833v4l.org - online PHP shell with 250+ PHP versions
https://3v4l.org/Visit 3v4l.org: an online shell that allows you to run your code on my server - 284The PhpStorm Blog | The JetBrains Blog
https://blog.jetbrains.com/phpstorm/tag/php-annotated-monthly/Get the latest PhpStorm updates and discover the most recent developments in the world of PHP - 285Official repository of the AWS SDK for PHP (@awsforphp)
https://github.com/aws/aws-sdk-phpOfficial repository of the AWS SDK for PHP (@awsforphp) - aws/aws-sdk-php - 286Official PHP client for Elasticsearch.
https://github.com/elastic/elasticsearch-phpOfficial PHP client for Elasticsearch. Contribute to elastic/elasticsearch-php development by creating an account on GitHub. - 287Doctrine Cache component
https://github.com/doctrine/cacheDoctrine Cache component. Contribute to doctrine/cache development by creating an account on GitHub. - 288[READ-ONLY] Validation library from CakePHP. This repo is a split of the main code that can be found in https://github.com/cakephp/cakephp
https://github.com/cakephp/validation[READ-ONLY] Validation library from CakePHP. This repo is a split of the main code that can be found in https://github.com/cakephp/cakephp - cakephp/validation - 289No Compromises
https://show.nocompromises.io/Two seasoned salty programming veterans talk best practices based on years of working with Laravel SaaS teams. - 290:computer: Send notifications to your desktop directly from your PHP script
https://github.com/jolicode/JoliNotif:computer: Send notifications to your desktop directly from your PHP script - jolicode/JoliNotif - 291A simple library to work with JSON Web Token and JSON Web Signature
https://github.com/lcobucci/jwtA simple library to work with JSON Web Token and JSON Web Signature - lcobucci/jwt - 292PHP Cookbook
https://www.oreilly.com/library/view/php-cookbook/9781098121310/If you're a PHP developer looking for proven solutions to common problems, this cookbook provides code recipes to help you resolve a variety of coding issues. PHP is a remarkably … - Selection from PHP Cookbook [Book] - 293Cache slam defense using a semaphore to prevent dogpile effect.
https://github.com/sobstel/metaphoreCache slam defense using a semaphore to prevent dogpile effect. - sobstel/metaphore - 294Functional Programming in PHP Book · Second Edition
https://www.functionalphp.com/Learn advanced and powerful functional programming techniques with the Functional Programming in PHP Book. - 295Eclipse Downloads | The Eclipse Foundation
https://www.eclipse.org/downloads/The Eclipse Foundation - home to a global community, the Eclipse IDE, Jakarta EE and over 415 open source projects, including runtimes, tools and frameworks. - 296API Platform
https://api-platform.comCreate REST and GraphQL APIs, scaffold Jamstack webapps, stream changes in real-time. - 297An ANSI to HTML5 converter
https://github.com/sensiolabs/ansi-to-htmlAn ANSI to HTML5 converter. Contribute to sensiolabs/ansi-to-html development by creating an account on GitHub. - 298Core Concepts
https://leanpub.com/securingphp-coreconceptsnull - 299application/hal builder / formatter for PHP 5.4+
https://github.com/blongden/halapplication/hal builder / formatter for PHP 5.4+. Contribute to blongden/hal development by creating an account on GitHub. - 300Validate and sanitize arrays and objects.
https://github.com/auraphp/Aura.FilterValidate and sanitize arrays and objects. Contribute to auraphp/Aura.Filter development by creating an account on GitHub. - 301[READ-ONLY] Easy to use Caching library with support for multiple caching backends. This repo is a split of the main code that can be found in https://github.com/cakephp/cakephp
https://github.com/cakephp/cache[READ-ONLY] Easy to use Caching library with support for multiple caching backends. This repo is a split of the main code that can be found in https://github.com/cakephp/cakephp - cakephp/cache - 302PHP 5.3+ oAuth 1/2 Client Library
https://github.com/daviddesberg/PHPoAuthLibPHP 5.3+ oAuth 1/2 Client Library. Contribute to daviddesberg/PHPoAuthLib development by creating an account on GitHub. - 303Online PHP Sandbox on Steroids!
https://phpsandbox.ioPHP Sandbox is an online code sandbox for PHP that makes prototyping and sharing of PHP Projects swift and painless. - 304Signaling PHP
https://leanpub.com/signalingphpnull - 305Elastic — The Search AI Company
https://www.elastic.co/.Power insights and outcomes with The Elastic Search AI Platform. See into your data and find answers that matter with enterprise solutions designed to help you accelerate time to insight. Try Elastic ... - 306OAuth 1 Client
https://github.com/thephpleague/oauth1-clientOAuth 1 Client. Contribute to thephpleague/oauth1-client development by creating an account on GitHub. - 307Output complex, flexible, AJAX/RESTful data structures.
https://github.com/thephpleague/fractalOutput complex, flexible, AJAX/RESTful data structures. - thephpleague/fractal - 308File uploads with validation and storage strategies
https://github.com/brandonsavage/UploadFile uploads with validation and storage strategies - brandonsavage/Upload - 309Laravel - The PHP Framework For Web Artisans
https://laravel.com/docs/master/valet.Laravel is a PHP web application framework with expressive, elegant syntax. We’ve already laid the foundation — freeing you to create without sweating the small things. - 310The Grumpy Programmer's PHPUnit Cookbook
https://leanpub.com/grumpy-phpunitA no-nonsense guide on how to use PHPUnit - 311Bernard is a multi-backend PHP library for creating background jobs for later processing.
https://github.com/bernardphp/bernardBernard is a multi-backend PHP library for creating background jobs for later processing. - bernardphp/bernard - 312Quickly and easily expose Doctrine entities as REST resource endpoints with the use of simple configuration with annotations, yaml, json or a PHP array.
https://github.com/leedavis81/drestQuickly and easily expose Doctrine entities as REST resource endpoints with the use of simple configuration with annotations, yaml, json or a PHP array. - leedavis81/drest - 313Decimal handling as value object instead of plain strings or floats.
https://github.com/php-collective/decimal-objectDecimal handling as value object instead of plain strings or floats. - php-collective/decimal-object - 314Immutable value object for IPv4 and IPv6 addresses, including helper methods and Doctrine support.
https://github.com/darsyn/ipImmutable value object for IPv4 and IPv6 addresses, including helper methods and Doctrine support. - darsyn/ip - 315PHP Town Hall
https://phptownhall.com/PHP Town Hall is a podcast from Ben Edmunds and Matt Trask that raises questions about current events (or upcoming things) in the PHP community, with different guests each episode. - 316The most popular PHP library for use with the Twitter OAuth REST API.
https://github.com/abraham/twitteroauthThe most popular PHP library for use with the Twitter OAuth REST API. - abraham/twitteroauth - 317Platform-Agnostic Security Tokens
https://github.com/paragonie/pasetoPlatform-Agnostic Security Tokens. Contribute to paragonie/paseto development by creating an account on GitHub. - 318PHP's best friend for the terminal.
https://github.com/thephpleague/climatePHP's best friend for the terminal. Contribute to thephpleague/climate development by creating an account on GitHub. - 319Laravel News Podcast
https://podcast.laravel-news.com/The Laravel News Podcast brings you all the latest news and events related to the Laravel PHP Framework - 320Lock library to provide serialized execution of PHP code.
https://github.com/php-lock/lockLock library to provide serialized execution of PHP code. - php-lock/lock - 321Content Negotiation tools for PHP.
https://github.com/willdurand/NegotiationContent Negotiation tools for PHP. Contribute to willdurand/Negotiation development by creating an account on GitHub. - 322A Oembed consumer library, that gives you information about urls. It helps you replace urls to youtube or vimeo for example, with their html embed code. It has advanced features like offline support, responsive embeds and caching support.
https://github.com/mpratt/EmberaA Oembed consumer library, that gives you information about urls. It helps you replace urls to youtube or vimeo for example, with their html embed code. It has advanced features like offline suppor... - 323Laravel - The PHP Framework For Web Artisans
https://laravel.com/docs/master/homesteadLaravel is a PHP web application framework with expressive, elegant syntax. We’ve already laid the foundation — freeing you to create without sweating the small things. - 324XML Parsing with PHP | php[architect]
https://www.phparch.com/books/xml-parsing-with-php/This edition covers parsing and validating XML documents, leveraging XPath expressions, and working with namespaces as well as how to create and modify XML files programmatically. Each chapter contains examples illustrating how to use the different XML extensions at your disposal. - 325A lightweight lexical string parser for BBCode styled markup.
https://github.com/milesj/decodaA lightweight lexical string parser for BBCode styled markup. - milesj/decoda - 326Provide TeX-Hyphenation to PHP
https://github.com/heiglandreas/Org_Heigl_HyphenatorProvide TeX-Hyphenation to PHP. Contribute to heiglandreas/Org_Heigl_Hyphenator development by creating an account on GitHub. - 327👮 A PHP desktop/mobile user agent parser with support for Laravel, based on Mobiledetect
https://github.com/jenssegers/agent👮 A PHP desktop/mobile user agent parser with support for Laravel, based on Mobiledetect - jenssegers/agent - 328The Laravel Podcast
https://laravelpodcast.com/The Laravel Podcast brings you Laravel and PHP development news and discussion. - 329North Meets South Web Podcast
https://www.northmeetssouth.audio/Jake Bennett and Michael Dyrynda conquer a 14.5 hour time difference to talk about life as web developers - 330Mostly Technical
https://mostlytechnical.com/Hosted by Ian Landsman and Aaron Francis, Mostly Technical is a lively discussion on Laravel, business, and an eclectic mix of related topics. - 331PHP-CPP - A C++ library for developing PHP extensions
https://www.php-cpp.com/PHP-CPP is a C++ library for developing PHP extensions. Use and extend PHP-CPP's well documented and easy to use classes to build native extensions for PHP. - 332Thin assertion library for use in libraries and business-model
https://github.com/beberlei/assertThin assertion library for use in libraries and business-model - beberlei/assert - 333The VObject library for PHP allows you to easily parse and manipulate iCalendar and vCard objects
https://github.com/sabre-io/vobject:date: The VObject library for PHP allows you to easily parse and manipulate iCalendar and vCard objects - GitHub - sabre-io/vobject: The VObject library for PHP allows you to easily parse and man... - 334PHP Library that implements several messaging patterns for RabbitMQ
https://github.com/php-amqplib/ThumperPHP Library that implements several messaging patterns for RabbitMQ - php-amqplib/Thumper - 335Over Engineered
https://overengineered.fm/A podcast where we explore unimportant programming questions (mostly PHP/Laravel/JavaScript) in extreme detail. - 336Library to parse, format and convert byte units
https://github.com/gabrielelana/byte-unitsLibrary to parse, format and convert byte units. Contribute to gabrielelana/byte-units development by creating an account on GitHub. - 337Laravel Herd
https://herd.laravel.com/Laravel Development perfected - One click PHP development environment. - 338Arbitrary-precision arithmetic library for PHP
https://github.com/brick/mathArbitrary-precision arithmetic library for PHP. Contribute to brick/math development by creating an account on GitHub. - 339Code highlighting with Shiki in PHP
https://github.com/spatie/shiki-phpCode highlighting with Shiki in PHP. Contribute to spatie/shiki-php development by creating an account on GitHub. - 340ColorJizz is a PHP library for manipulating and converting colors.
https://github.com/mikeemoo/ColorJizz-PHPColorJizz is a PHP library for manipulating and converting colors. - mikeemoo/ColorJizz-PHP - 341Provides an object-oriented API to sanitize untrusted HTML input for safe insertion into a document's DOM.
https://github.com/symfony/html-sanitizerProvides an object-oriented API to sanitize untrusted HTML input for safe insertion into a document's DOM. - symfony/html-sanitizer - 342Domain-Driven Design in PHP
https://leanpub.com/ddd-in-phpMaster Domain-Driven Design Tactical patterns: Entities, Value Objects, Services, Domain Events, Aggregates, Factories, Repositories and Application Services. - 343PHP implementation of JSON schema. Fork of the http://jsonschemaphpv.sourceforge.net/ project
https://github.com/jsonrainbow/json-schemaPHP implementation of JSON schema. Fork of the http://jsonschemaphpv.sourceforge.net/ project - GitHub - jsonrainbow/json-schema: PHP implementation of JSON schema. Fork of the http://jsonschemaph... - 344Extracts information about web pages, like youtube videos, twitter statuses or blog articles.
https://github.com/essence/essenceExtracts information about web pages, like youtube videos, twitter statuses or blog articles. - essence/essence - 345The Official MongoDB PHP driver
https://github.com/mongodb/mongo-php-driverThe Official MongoDB PHP driver. Contribute to mongodb/mongo-php-driver development by creating an account on GitHub. - 346Generates a PHP SDK based on a WSDL, simple and powerful, WSDL to PHP
https://github.com/WsdlToPhp/PackageGeneratorGenerates a PHP SDK based on a WSDL, simple and powerful, WSDL to PHP - WsdlToPhp/PackageGenerator - 347php[architect] Magazine - The Journal for PHP Programmers
https://www.phparch.com/magazine/php[architect] is the monthly journal for PHP developers. Each issue is carefully curated and reviewed. A PHP magazine in print & digital editions. - 348Parser for Markdown and Markdown Extra derived from the original Markdown.pl by John Gruber.
https://github.com/michelf/php-markdownParser for Markdown and Markdown Extra derived from the original Markdown.pl by John Gruber. - michelf/php-markdown - 349Podcast Episodes Archive | php[architect]
https://www.phparch.com/podcast/The site for PHP professionals, Magazine, Training, Books, Conferences - 350Library for (de-)serializing data of any complexity (supports JSON, and XML)
https://github.com/schmittjoh/serializerLibrary for (de-)serializing data of any complexity (supports JSON, and XML) - schmittjoh/serializer - 351Skeleton Application for Laminas API Tools
https://github.com/laminas-api-tools/api-tools-skeletonSkeleton Application for Laminas API Tools. Contribute to laminas-api-tools/api-tools-skeleton development by creating an account on GitHub. - 352PHP Database Migrations for Everyone
https://github.com/cakephp/phinxPHP Database Migrations for Everyone. Contribute to cakephp/phinx development by creating an account on GitHub. - 353Standards compliant HTML filter written in PHP
https://github.com/ezyang/htmlpurifierStandards compliant HTML filter written in PHP. Contribute to ezyang/htmlpurifier development by creating an account on GitHub. - 354A powerful command line application framework for PHP. It's an extensible, flexible component, You can build your command-based application in seconds!
https://github.com/c9s/CLIFrameworkA powerful command line application framework for PHP. It's an extensible, flexible component, You can build your command-based application in seconds! - c9s/CLIFramework - 355An Elegant CLI Library for PHP
https://github.com/nategood/commandoAn Elegant CLI Library for PHP. Contribute to nategood/commando development by creating an account on GitHub. - 356:snowflake: A PHP library for generating universally unique identifiers (UUIDs).
https://github.com/ramsey/uuid:snowflake: A PHP library for generating universally unique identifiers (UUIDs). - ramsey/uuid - 357ua-parser/php at master · tobie/ua-parser
https://github.com/tobie/ua-parser/tree/master/phpA multi-language port of Browserscope's user agent parser. - tobie/ua-parser - 358A library for handling physical quantities and the units of measure in which they're represented.
https://github.com/triplepoint/php-units-of-measureA library for handling physical quantities and the units of measure in which they're represented. - triplepoint/php-units-of-measure - 359Simple and effective multi-format Web API Server to host your PHP API as Pragmatic REST and/or RESTful API
https://github.com/Luracast/RestlerSimple and effective multi-format Web API Server to host your PHP API as Pragmatic REST and/or RESTful API - Luracast/Restler - 360`LINQ to Object` inspired DSL for PHP
https://github.com/akanehara/ginq`LINQ to Object` inspired DSL for PHP. Contribute to akanehara/ginq development by creating an account on GitHub. - 361Redis - The Real-time Data Platform
https://redis.io/Developers love Redis. Unlock the full potential of the Redis database with Redis Enterprise and start building blazing fast apps. - 362Message Queue, Job Queue, Broadcasting, WebSockets packages for PHP, Symfony, Laravel, Magento. DEVELOPMENT REPOSITORY - provided by Forma-Pro
https://github.com/php-enqueue/enqueue-devMessage Queue, Job Queue, Broadcasting, WebSockets packages for PHP, Symfony, Laravel, Magento. DEVELOPMENT REPOSITORY - provided by Forma-Pro - php-enqueue/enqueue-dev - 363Extensive, portable and performant handling of UTF-8 and grapheme clusters for PHP
https://github.com/nicolas-grekas/Patchwork-UTF8Extensive, portable and performant handling of UTF-8 and grapheme clusters for PHP - nicolas-grekas/Patchwork-UTF8 - 364The place to keep your cache.
https://github.com/tedious/StashThe place to keep your cache. Contribute to tedious/Stash development by creating an account on GitHub. - 365A lightweight php class for formatting sql statements. Handles automatic indentation and syntax highlighting.
https://github.com/jdorn/sql-formatter/A lightweight php class for formatting sql statements. Handles automatic indentation and syntax highlighting. - jdorn/sql-formatter - 366An HTML5 parser and serializer for PHP.
https://github.com/Masterminds/html5-phpAn HTML5 parser and serializer for PHP. Contribute to Masterminds/html5-php development by creating an account on GitHub. - 367The most awesome validation engine ever created for PHP
https://github.com/Respect/ValidationThe most awesome validation engine ever created for PHP - Respect/Validation - 368A PHP library for command-line argument processing
https://github.com/getopt-php/getopt-phpA PHP library for command-line argument processing - getopt-php/getopt-php - 369A beautiful yet powerful syntax highlighter
https://github.com/shikijs/shikiA beautiful yet powerful syntax highlighter. Contribute to shikijs/shiki development by creating an account on GitHub. - 370The Universal Device Detection library will parse any User Agent and detect the browser, operating system, device used (desktop, tablet, mobile, tv, cars, console, etc.), brand and model.
https://github.com/matomo-org/device-detectorThe Universal Device Detection library will parse any User Agent and detect the browser, operating system, device used (desktop, tablet, mobile, tv, cars, console, etc.), brand and model. - GitHub... - 371Database migrations for PHP ala ActiveRecord Migrations with support for MySQL, Postgres, SQLite
https://github.com/ruckus/ruckusing-migrationsDatabase migrations for PHP ala ActiveRecord Migrations with support for MySQL, Postgres, SQLite - ruckus/ruckusing-migrations - 372Yet Another LINQ to Objects for PHP [Simplified BSD]
https://github.com/Athari/YaLinqoYet Another LINQ to Objects for PHP [Simplified BSD] - Athari/YaLinqo - 373Map nested JSON structures to PHP classes
https://github.com/JsonMapper/JsonMapperMap nested JSON structures to PHP classes. Contribute to JsonMapper/JsonMapper development by creating an account on GitHub. - 374[READ-ONLY] Collection library in CakePHP. This repo is a split of the main code that can be found in https://github.com/cakephp/cakephp
https://github.com/cakephp/collection[READ-ONLY] Collection library in CakePHP. This repo is a split of the main code that can be found in https://github.com/cakephp/cakephp - cakephp/collection - 375PHP Integrated Query, a real LINQ library for PHP
https://github.com/TimeToogo/PinqPHP Integrated Query, a real LINQ library for PHP. Contribute to TimeToogo/Pinq development by creating an account on GitHub. - 376The PHP deployment tool with support for popular frameworks out of the box
https://github.com/deployphp/deployerThe PHP deployment tool with support for popular frameworks out of the box - deployphp/deployer - 377PPM is a process manager, supercharger and load balancer for modern PHP applications.
https://github.com/php-pm/php-pmPPM is a process manager, supercharger and load balancer for modern PHP applications. - php-pm/php-pm - 378A thin PSR-6 cache wrapper with a generic interface to various caching backends emphasising cache tagging and indexing.
https://github.com/apix/cacheA thin PSR-6 cache wrapper with a generic interface to various caching backends emphasising cache tagging and indexing. - apix/cache - 379Elastica is a PHP client for elasticsearch
https://github.com/ruflin/ElasticaElastica is a PHP client for elasticsearch. Contribute to ruflin/Elastica development by creating an account on GitHub. - 380Library for converting units and sizes in PHP
https://github.com/Crisu83/php-conversionLibrary for converting units and sizes in PHP. Contribute to crisu83/php-conversion development by creating an account on GitHub. - 381PHP client for beanstalkd queue
https://github.com/pheanstalk/pheanstalkPHP client for beanstalkd queue. Contribute to pheanstalk/pheanstalk development by creating an account on GitHub. - 382PHP bindings for Tarantool Queue.
https://github.com/tarantool-php/queuePHP bindings for Tarantool Queue. Contribute to tarantool-php/queue development by creating an account on GitHub. - 383PHP library - Validators for standards from ISO, International Finance, Public Administrations, GS1, Manufacturing Industry, Phone numbers & Zipcodes for many countries
https://github.com/ronanguilloux/IsoCodesPHP library - Validators for standards from ISO, International Finance, Public Administrations, GS1, Manufacturing Industry, Phone numbers & Zipcodes for many countries - ronanguilloux/IsoCodes - 384PHP version of Google's phone number handling library
https://github.com/giggsey/libphonenumber-for-phpPHP version of Google's phone number handling library - giggsey/libphonenumber-for-php - 385:atom: Social (OAuth1\OAuth2\OpenID\OpenIDConnect) sign with PHP :shipit:
https://github.com/socialConnect/auth:atom: Social (OAuth1\OAuth2\OpenID\OpenIDConnect) sign with PHP :shipit: - SocialConnect/auth - 386Caching implementation with a variety of storage options, as well as codified caching strategies for callbacks, classes, and output
https://github.com/laminas/laminas-cacheCaching implementation with a variety of storage options, as well as codified caching strategies for callbacks, classes, and output - laminas/laminas-cache - 387Lovely PHP wrapper for using the command-line
https://github.com/MrRio/shellwrapLovely PHP wrapper for using the command-line. Contribute to MrRio/shellwrap development by creating an account on GitHub. - 388Convert HTML to Markdown with PHP
https://github.com/thephpleague/html-to-markdownConvert HTML to Markdown with PHP. Contribute to thephpleague/html-to-markdown development by creating an account on GitHub. - 389JSON Lint for PHP
https://github.com/Seldaek/jsonlintJSON Lint for PHP. Contribute to Seldaek/jsonlint development by creating an account on GitHub. - 390Brew PHP switcher is a simple shell script to switch your apache and CLI quickly between major versions of PHP. If you support multiple products/projects that are built using either brand new or old legacy PHP functionality. For users of Homebrew (or brew for short) currently only.
https://github.com/philcook/brew-php-switcherBrew PHP switcher is a simple shell script to switch your apache and CLI quickly between major versions of PHP. If you support multiple products/projects that are built using either brand new or ol... - 391Multi-provider authentication framework for PHP
https://github.com/opauth/opauthMulti-provider authentication framework for PHP. Contribute to opauth/opauth development by creating an account on GitHub. - 392A powerful schema validator!
https://github.com/romaricdrigon/MetaYamlA powerful schema validator! Contribute to romaricdrigon/MetaYaml development by creating an account on GitHub. - 393Mobile_Detect is a lightweight PHP class for detecting mobile devices (including tablets). It uses the User-Agent string combined with specific HTTP headers to detect the mobile environment.
https://github.com/serbanghita/Mobile-DetectMobile_Detect is a lightweight PHP class for detecting mobile devices (including tablets). It uses the User-Agent string combined with specific HTTP headers to detect the mobile environment. - serb... - 394🔡 Portable ASCII library - performance optimized (ascii) string functions for PHP.
https://github.com/voku/portable-ascii🔡 Portable ASCII library - performance optimized (ascii) string functions for PHP. - voku/portable-ascii - 395Light and extendable schema validation library
https://github.com/serkin/VolanLight and extendable schema validation library. Contribute to serkin/volan development by creating an account on GitHub. - 396Accelerated Container Application Development
https://www.docker.com/Docker is a platform designed to help developers build, share, and run container applications. We handle the tedious setup, so you can focus on the code. - 397A great looking and easy-to-use photo-management-system you can run on your server, to manage and share photos.
https://github.com/electerious/LycheeA great looking and easy-to-use photo-management-system you can run on your server, to manage and share photos. - electerious/Lychee - 398Takes care of Apple push notifications (APNS) in your PHP projects.
https://github.com/mac-cain13/notificatoTakes care of Apple push notifications (APNS) in your PHP projects. - mac-cain13/notificato - 399Hprose is a cross-language RPC. This project is Hprose 3.0 for PHP
https://github.com/hprose/hprose-phpHprose is a cross-language RPC. This project is Hprose 3.0 for PHP - hprose/hprose-php - 400Easy integration with OAuth 2.0 service providers.
https://github.com/thephpleague/oauth2-clientEasy integration with OAuth 2.0 service providers. - thephpleague/oauth2-client - 401Annotations Docblock Parser
https://github.com/doctrine/annotationsAnnotations Docblock Parser. Contribute to doctrine/annotations development by creating an account on GitHub. - 402All PHP functions, rewritten to throw exceptions instead of returning false
https://github.com/thecodingmachine/safeAll PHP functions, rewritten to throw exceptions instead of returning false - thecodingmachine/safe - 403Send your projects up in the clouds
https://github.com/rocketeers/rocketeerSend your projects up in the clouds. Contribute to rocketeers/rocketeer development by creating an account on GitHub. - 404Standalone PHP library for easy devices notifications push.
https://github.com/Ph3nol/NotificationPusherStandalone PHP library for easy devices notifications push. - Ph3nol/NotificationPusher - 405A framework agnostic PHP library to build chat bots
https://github.com/botman/botmanA framework agnostic PHP library to build chat bots - botman/botman - 406A powerful and easy-to-use PHP SDK for the Mistral AI API, allowing seamless integration of advanced AI-powered features into your PHP projects.
https://github.com/SoftCreatR/php-mistral-ai-sdkA powerful and easy-to-use PHP SDK for the Mistral AI API, allowing seamless integration of advanced AI-powered features into your PHP projects. - SoftCreatR/php-mistral-ai-sdk - 407A PHP Library to easily send push notifications with the Pushwoosh REST Web Services.
https://github.com/gomoob/php-pushwooshA PHP Library to easily send push notifications with the Pushwoosh REST Web Services. - gomoob/php-pushwoosh - 408Internationalization tools, particularly message translation.
https://github.com/auraphp/Aura.IntlInternationalization tools, particularly message translation. - auraphp/Aura.Intl - 409An object-oriented option parser library for PHP, which supports type constraints, flag, multiple flag, multiple values, required value checking
https://github.com/c9s/GetOptionKitAn object-oriented option parser library for PHP, which supports type constraints, flag, multiple flag, multiple values, required value checking - c9s/GetOptionKit - 410php 5.3 Migration Manager
https://github.com/icomefromthenet/Migrationsphp 5.3 Migration Manager. Contribute to icomefromthenet/Migrations development by creating an account on GitHub. - 411Database version control, made easy!
https://github.com/victorstanciu/dbvDatabase version control, made easy! Contribute to victorstanciu/dbv development by creating an account on GitHub. - 412Builds PHP so that multiple versions can be used side by side.
https://github.com/php-build/php-buildBuilds PHP so that multiple versions can be used side by side. - php-build/php-build - 413Optimizes class loading performance by generating a single PHP file containing all of the autoloaded files.
https://github.com/ClassPreloader/ClassPreloaderOptimizes class loading performance by generating a single PHP file containing all of the autoloaded files. - ClassPreloader/ClassPreloader - 414Interactive voting results for PHP RFC process.
https://github.com/beberlei/php-rfc-watchInteractive voting results for PHP RFC process. Contribute to beberlei/php-rfc-watch development by creating an account on GitHub. - 415Performant pure-PHP AMQP (RabbitMQ) sync/async (ReactPHP) library
https://github.com/jakubkulhan/bunnyPerformant pure-PHP AMQP (RabbitMQ) sync/async (ReactPHP) library - jakubkulhan/bunny - 416Simple migrations system for php
https://github.com/davedevelopment/phpmigSimple migrations system for php. Contribute to davedevelopment/phpmig development by creating an account on GitHub. - 417Efficient, easy-to-use, and fast PHP JSON stream parser
https://github.com/halaxa/json-machineEfficient, easy-to-use, and fast PHP JSON stream parser - halaxa/json-machine - 418A beautiful, fully open-source, tunneling service - written in pure PHP
https://github.com/beyondcode/exposeA beautiful, fully open-source, tunneling service - written in pure PHP - beyondcode/expose - 419🚦 The open-source status page system.
https://github.com/cachethq/cachet🚦 The open-source status page system. Contribute to cachethq/cachet development by creating an account on GitHub. - 420A simple PHP GitHub API client, Object Oriented, tested and documented.
https://github.com/KnpLabs/php-github-apiA simple PHP GitHub API client, Object Oriented, tested and documented. - KnpLabs/php-github-api - 421Laravel Serializable Closure provides an easy and secure way to serialize closures in PHP.
https://github.com/laravel/serializable-closureLaravel Serializable Closure provides an easy and secure way to serialize closures in PHP. - laravel/serializable-closure - 422Elegant SSH tasks for PHP.
https://github.com/laravel/envoyElegant SSH tasks for PHP. Contribute to laravel/envoy development by creating an account on GitHub. - 423PHP client library for the Square Connect APIs
https://github.com/square/connect-php-sdkPHP client library for the Square Connect APIs. Contribute to square/connect-php-sdk development by creating an account on GitHub. - 424[READ-ONLY] Provides support for message translation and localization for dates and numbers. This repo is a split of the main code that can be found in https://github.com/cakephp/cakephp
https://github.com/cakephp/i18n[READ-ONLY] Provides support for message translation and localization for dates and numbers. This repo is a split of the main code that can be found in https://github.com/cakephp/cakephp - cakephp/... - 425:passport_control: Helper for Google's new noCAPTCHA (reCAPTCHA v2 & v3)
https://github.com/ARCANEDEV/noCAPTCHA:passport_control: Helper for Google's new noCAPTCHA (reCAPTCHA v2 & v3) - ARCANEDEV/noCAPTCHA - 426A unified front-end for different queuing backends. Includes a REST server, CLI interface and daemon runners.
https://github.com/CoderKungfu/php-queueA unified front-end for different queuing backends. Includes a REST server, CLI interface and daemon runners. - CoderKungfu/php-queue - 427Zephir is a compiled high-level language aimed to ease the creation of C-extensions for PHP
https://github.com/zephir-lang/zephirZephir is a compiled high-level language aimed to ease the creation of C-extensions for PHP - zephir-lang/zephir - 428A virtual machine for executing programs written in Hack.
https://github.com/facebook/hhvmA virtual machine for executing programs written in Hack. - facebook/hhvm - 429Cilex a lightweight framework for creating PHP CLI scripts inspired by Silex
https://github.com/Cilex/CilexCilex a lightweight framework for creating PHP CLI scripts inspired by Silex - Cilex/Cilex - 430Converts a string to a slug. Includes integrations for Symfony, Silex, Laravel, Zend Framework 2, Twig, Nette and Latte.
https://github.com/cocur/slugifyConverts a string to a slug. Includes integrations for Symfony, Silex, Laravel, Zend Framework 2, Twig, Nette and Latte. - cocur/slugify - 431A PHP parser for TOML
https://github.com/yosymfony/tomlA PHP parser for TOML. Contribute to yosymfony/toml development by creating an account on GitHub. - 432Catches mail and serves it through a dream.
https://github.com/sj26/mailcatcherCatches mail and serves it through a dream. Contribute to sj26/mailcatcher development by creating an account on GitHub. - 433Map nested JSON structures onto PHP classes
https://github.com/cweiske/jsonmapperMap nested JSON structures onto PHP classes. Contribute to cweiske/jsonmapper development by creating an account on GitHub. - 434PeachPie - the PHP compiler and runtime for .NET and .NET Core
https://github.com/peachpiecompiler/peachpiePeachPie - the PHP compiler and runtime for .NET and .NET Core - peachpiecompiler/peachpie - 435A REPL for PHP
https://github.com/bobthecow/psyshA REPL for PHP. Contribute to bobthecow/psysh development by creating an account on GitHub. - 436Loads environment variables from `.env` to `getenv()`, `$_ENV` and `$_SERVER` automagically.
https://github.com/vlucas/phpdotenvLoads environment variables from `.env` to `getenv()`, `$_ENV` and `$_SERVER` automagically. - vlucas/phpdotenv - 437A web interface for MySQL and MariaDB
https://github.com/phpmyadmin/phpmyadminA web interface for MySQL and MariaDB. Contribute to phpmyadmin/phpmyadmin development by creating an account on GitHub. - 438CRON for PHP: Calculate the next or previous run date and determine if a CRON expression is due
https://github.com/mtdowling/cron-expressionCRON for PHP: Calculate the next or previous run date and determine if a CRON expression is due - mtdowling/cron-expression - 439A very lightweight library to handle notifications the smart way.
https://github.com/namshi/notificatorA very lightweight library to handle notifications the smart way. - namshi/notificator - 440Docker-based development-only dependency manager. macOS, Linux, and WSL2-only and installs via PHP's Composer... for now.
https://github.com/tighten/takeoutDocker-based development-only dependency manager. macOS, Linux, and WSL2-only and installs via PHP's Composer... for now. - tighten/takeout - 441A multithreaded application server for PHP, written in PHP.
https://github.com/appserver-io/appserverA multithreaded application server for PHP, written in PHP. - appserver-io/appserver - 442🤯 High-performance PHP application server, process manager written in Go and powered with plugins
https://github.com/roadrunner-server/roadrunner🤯 High-performance PHP application server, process manager written in Go and powered with plugins - roadrunner-server/roadrunner - 443CLI App and library to manage apc & opcache.
https://github.com/gordalina/cachetoolCLI App and library to manage apc & opcache. Contribute to gordalina/cachetool development by creating an account on GitHub. - 444Serialize and deserialize PHP structures to a variety of representations
https://github.com/laminas/laminas-serializerSerialize and deserialize PHP structures to a variety of representations - laminas/laminas-serializer - 445Provides a unified interface to local and remote authentication systems.
https://github.com/auraphp/Aura.AuthProvides a unified interface to local and remote authentication systems. - auraphp/Aura.Auth - 446Mailgun's Official SDK for PHP
https://github.com/mailgun/mailgun-phpMailgun's Official SDK for PHP. Contribute to mailgun/mailgun-php development by creating an account on GitHub. - 447Build standalone PHP binary on Linux, macOS, FreeBSD, Windows, with PHP project together, with popular extensions included.
https://github.com/crazywhalecc/static-php-cliBuild standalone PHP binary on Linux, macOS, FreeBSD, Windows, with PHP project together, with popular extensions included. - crazywhalecc/static-php-cli - 448Brew & manage PHP versions in pure PHP at HOME
https://github.com/phpbrew/phpbrewBrew & manage PHP versions in pure PHP at HOME. Contribute to phpbrew/phpbrew development by creating an account on GitHub. - 449A pure PHP implementation of the MessagePack serialization format / msgpack.org[PHP]
https://github.com/rybakit/msgpack.phpA pure PHP implementation of the MessagePack serialization format / msgpack.org[PHP] - rybakit/msgpack.php - 450Laravel News
https://laravel-news.com/Laravel News is the official blog of Laravel. Every day bringing you the latest news, tutorials, and packages for the framework. - 451Highly-extensible PHP Markdown parser which fully supports the CommonMark and GFM specs.
https://github.com/thephpleague/commonmarkHighly-extensible PHP Markdown parser which fully supports the CommonMark and GFM specs. - thephpleague/commonmark - 452PHP library for the Stripe API.
https://github.com/stripe/stripe-phpPHP library for the Stripe API. . Contribute to stripe/stripe-php development by creating an account on GitHub. - 453Pagination for PHP.
https://github.com/whiteoctober/PagerfantaPagination for PHP. Contribute to whiteoctober/Pagerfanta development by creating an account on GitHub. - 454Command-Line Interface tools
https://github.com/auraphp/Aura.CliCommand-Line Interface tools. Contribute to auraphp/Aura.Cli development by creating an account on GitHub. - 455A flexible and feature-complete Redis client for PHP.
https://github.com/predis/predisA flexible and feature-complete Redis client for PHP. - predis/predis - 456A PHP library for communicating with the Twilio REST API and generating TwiML.
https://github.com/twilio/twilio-phpA PHP library for communicating with the Twilio REST API and generating TwiML. - twilio/twilio-php - 457Valitron is a simple, elegant, stand-alone validation library with NO dependencies
https://github.com/vlucas/valitronValitron is a simple, elegant, stand-alone validation library with NO dependencies - vlucas/valitron - 458LLPhant - A comprehensive PHP Generative AI Framework using OpenAI GPT 4. Inspired by Langchain
https://github.com/theodo-group/LLPhantLLPhant - A comprehensive PHP Generative AI Framework using OpenAI GPT 4. Inspired by Langchain - theodo-group/LLPhant - 459:elephant: A Circuit Breaker pattern implementation for PHP applications.
https://github.com/ackintosh/ganesha:elephant: A Circuit Breaker pattern implementation for PHP applications. - ackintosh/ganesha - 460Better Markdown Parser in PHP
https://github.com/erusev/parsedownBetter Markdown Parser in PHP. Contribute to erusev/parsedown development by creating an account on GitHub. - 461🖥 Build beautiful PHP CLI menus. Simple yet Powerful. Expressive DSL.
https://github.com/php-school/cli-menu🖥 Build beautiful PHP CLI menus. Simple yet Powerful. Expressive DSL. - php-school/cli-menu - 462Easily install PHP extensions in Docker containers
https://github.com/mlocati/docker-php-extension-installerEasily install PHP extensions in Docker containers - mlocati/docker-php-extension-installer - 463The most widely used PHP client for RabbitMQ
https://github.com/php-amqplib/php-amqplibThe most widely used PHP client for RabbitMQ. Contribute to php-amqplib/php-amqplib development by creating an account on GitHub. - 464"結巴"中文分詞:做最好的 PHP 中文分詞、中文斷詞組件。 / "Jieba" (Chinese for "to stutter") Chinese text segmentation: built to be the best PHP Chinese word segmentation module.
https://github.com/fukuball/jieba-php"結巴"中文分詞:做最好的 PHP 中文分詞、中文斷詞組件。 / "Jieba" (Chinese for "to stutter") Chinese text segmentation: built to be the best PHP Chinese word segmentation module. - fukuball/ji... - 465Build software better, together
https://github.com/symfony/dotenv-GitHub is where people build software. More than 100 million people use GitHub to discover, fork, and contribute to over 420 million projects. - 466A Parser for CSS Files written in PHP. Allows extraction of CSS files into a data structure, manipulation of said structure and output as (optimized) CSS
https://github.com/MyIntervals/PHP-CSS-ParserA Parser for CSS Files written in PHP. Allows extraction of CSS files into a data structure, manipulation of said structure and output as (optimized) CSS - MyIntervals/PHP-CSS-Parser - 467A super fast, highly extensible markdown parser for PHP
https://github.com/cebe/markdownA super fast, highly extensible markdown parser for PHP - cebe/markdown - 468Simple web interface to manage Redis databases.
https://github.com/ErikDubbelboer/phpRedisAdminSimple web interface to manage Redis databases. Contribute to erikdubbelboer/phpRedisAdmin development by creating an account on GitHub. - 469⚡️ OpenAI PHP for Laravel is a supercharged PHP API client that allows you to interact with OpenAI API
https://github.com/openai-php/laravel⚡️ OpenAI PHP for Laravel is a supercharged PHP API client that allows you to interact with OpenAI API - openai-php/laravel - 470Unified, Docker 🐳 powered web development environments for macOS, Windows, and Linux
https://github.com/docksal/docksalUnified, Docker 🐳 powered web development environments for macOS, Windows, and Linux - docksal/docksal - 471Structured data outputs with LLMs, in PHP. Designed for simplicity, transparency, and control.
https://github.com/cognesy/instructor-phpStructured data outputs with LLMs, in PHP. Designed for simplicity, transparency, and control. - cognesy/instructor-php - 472A PHP library to support implementing representations for HATEOAS REST web services.
https://github.com/willdurand/HateoasA PHP library to support implementing representations for HATEOAS REST web services. - willdurand/Hateoas - 473Docker-based local PHP+Node.js web development environments
https://github.com/ddev/ddevDocker-based local PHP+Node.js web development environments - ddev/ddev - 474Laracon EU
https://www.youtube.com/@LaraconEULaracon EU is a 2-day event for people who are interested in learning Laravel and related technologies, or who want to share their knowledge with others. - 475PHP UK Conference
https://www.youtube.com/user/phpukconference/videosRecordings of sessions at our annual PHP UK Conference events. PHP UK Conferences are held annually at the end of February each year, in the capital city of London. Attended by hundreds of delegates, speakers, sponsors, partners and volunteer assistants, they are run by volunteers from the PHP community and elected committee members of PHP London. Delegates are typically professional web developers and managers, along with some general PHP enthusiasts/evangelists and employment recruiters. The events are a mix of split-track talk sessions, keynote presentations, panel sessions and unconference slots, along with space for exhibitors, various networking and social events, and a raffle. Costs are kept low and any profit made is used to fund PHP London throughout the rest of the year and/or is rolled into funding future conferences. - 476Learn PHP The Right Way - Full PHP Tutorial For Beginners & Advanced
https://www.youtube.com/playlist?list=PLr3d3QYzkw2xabQRUpcZ_IBk9W50M9pe-Hello & welcome to my first course "Learn PHP The Right Way". In this course, you will learn PHP from beginners level all the way to advanced. The "right way... - 477Laravel
https://www.youtube.com/channel/UCfO2GiQwb-cwJTb1CuRSkwgThe official YouTube channel of the Laravel PHP framework. We will update you on what's new in the world of Laravel, from the framework to our products like Forge or Vapor.
Related Articlesto learn about angular.
- 1Getting Started with PHP: Your First Steps into Web Development
- 2PHP Data Types and Variables: Comprehensive Beginner’s Guide
- 3Object-Oriented Programming in PHP: Classes, Objects, and More
- 4PHP Namespaces and Autoloading: Organizing Large Projects Efficiently
- 5Handling User Input in PHP: Forms, Validation, and Best Practices
- 6Building Dynamic Web Pages with PHP: Step-by-Step Guide
- 7Creating RESTful APIs with PHP: Complete Beginner’s Guide
- 8Integrating Third-Party APIs in PHP: Practical Guide
- 9Speeding Up Your PHP Applications: Tips and Techniques
- 10Securing Your PHP Applications: Best Practices for Developers
FAQ'sto learn more about Angular JS.
mail [email protected] to add more queries here 🔍.
- 1
how to learn php programming - 2
what do you mean by php programming language - 3
should i use php or javascript - 4
does php compile - 5
where does php run - 6
why is php important - 7
what programming language is php written in - 8
what can php be used for - 9
which programming language is similar to php - 10
when is php 7.4 end of life - 11
which software used for php programming - 12
how to run php programming - 13
is php a coding language - 14
why does php have a bad reputation - 15
do php programs work - 16
is php good for beginners - 17
how to improve php programming skills - 18
- 19
is php programming easy - 20
when was php programming language - 21
what does php do for websites - 22
where can i buy php programming - 23
where is php used - 24
who php programming language - 25
what php programming language - 26
what can php programming be used for - 27
why was php created - 28
will updating php break my site - 29
what is object oriented programming in php - 30
do i need to learn php for web development - 31
what is php programming - 32
is php the best for web development - 33
where does php scripting run - 34
what is the purpose of php programming language - 35
should you learn php - 36
should i use php - 37
what is php programming used for - 38
who invented php programming language - 39
should i learn php or python - 40
are php files dangerous - 41
what is the meaning of php in programming language - 42
- 43
is php a good programming language - 44
is php better than python - 45
why programmers hate php - 46
what programming language is php - 47
what type of programming language is php - 48
how to learn php programming app - 49
does php is a programming language - 50
why php is better than python - 51
is php a dying language - 52
how to study php programming - 53
how was php programming - 54
when was php invented - 55
will php become obsolete - 57
what does php stand for in programming - 58
can javascript and php work together - 59
why php is the best programming language - 61
who created php - 62
when was php programming - 63
where php programming is used - 64
where does php go in html - 65
which organization developed the php programming language - 66
what is php mean in programming - 67
who maintains php - 68
is php programming language - 69
how to write comments in php programming - 70
is php a high level programming language - 71
does php use html - 72
is php deprecated - 74
which software is best for php programming - 75
how to use php programming language - 76
when is php used - 77
how to start php programming - 78
when was php created - 79
which programming language does php resemble - 80
how to learn php programming step by step - 81
will php be replaced - 82
what is php programming language used for - 83
how can i start programming in php
More Sitesto check out once you're finished browsing here.
https://www.0x3d.site/0x3d is designed for aggregating information.https://nodejs.0x3d.site/NodeJS Online Directoryhttps://cross-platform.0x3d.site/Cross Platform Online Directoryhttps://open-source.0x3d.site/Open Source Online Directoryhttps://analytics.0x3d.site/Analytics Online Directoryhttps://javascript.0x3d.site/JavaScript Online Directoryhttps://golang.0x3d.site/GoLang Online Directoryhttps://python.0x3d.site/Python Online Directoryhttps://swift.0x3d.site/Swift Online Directoryhttps://rust.0x3d.site/Rust Online Directoryhttps://scala.0x3d.site/Scala Online Directoryhttps://ruby.0x3d.site/Ruby Online Directoryhttps://clojure.0x3d.site/Clojure Online Directoryhttps://elixir.0x3d.site/Elixir Online Directoryhttps://elm.0x3d.site/Elm Online Directoryhttps://lua.0x3d.site/Lua Online Directoryhttps://c-programming.0x3d.site/C Programming Online Directoryhttps://cpp-programming.0x3d.site/C++ Programming Online Directoryhttps://r-programming.0x3d.site/R Programming Online Directoryhttps://perl.0x3d.site/Perl Online Directoryhttps://java.0x3d.site/Java Online Directoryhttps://kotlin.0x3d.site/Kotlin Online Directoryhttps://php.0x3d.site/PHP Online Directoryhttps://react.0x3d.site/React JS Online Directoryhttps://angular.0x3d.site/Angular JS Online Directory